英特尔今天正式推出了用于 AI 工作负载的 Gaudi 3 加速器。新处理器的速度比 Nvidia 广受欢迎的 H100 和 H200 GPU(用于 AI 和 HPC)要慢,因此英特尔将其 Gaudi 3 的成功押注于其较低的价格和较低的总拥有成本 (TCO)。
继续阅读
Google AI TPU
英特尔今天正式推出了用于 AI 工作负载的 Gaudi 3 加速器。新处理器的速度比 Nvidia 广受欢迎的 H100 和 H200 GPU(用于 AI 和 HPC)要慢,因此英特尔将其 Gaudi 3 的成功押注于其较低的价格和较低的总拥有成本 (TCO)。
继续阅读
据《华尔街日报》援引知情人士消息,近日,高通已就收购事宜接洽英特尔。这将是近年来规模最大、影响最深远的交易之一。
继续阅读
以下是我对英特尔周四在纽约举行的“AI无处不在”(AI Everywhere)活动的总结。
继续阅读CXL 3.1是对CXL 3.0的一次渐进性改进,而后者则于一年多以前推出。作为系统中芯片、内存和存储之间关键的通信链路,CXL协议发挥着至关重要的作用。
继续阅读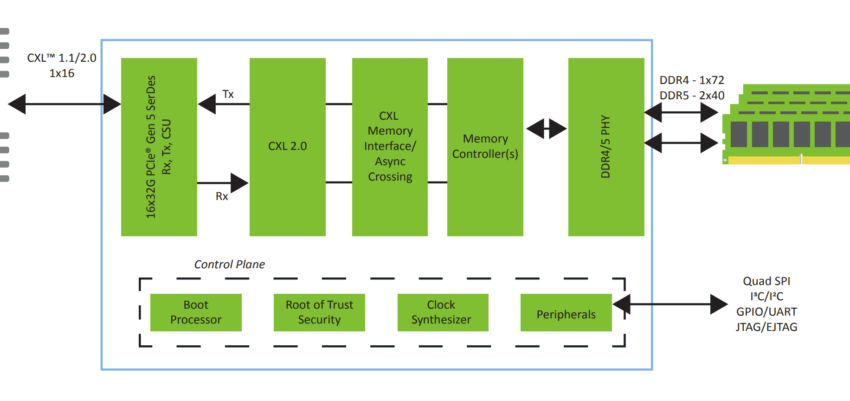
数据中心工作负载变得越来越复杂,需要越来越多的内存。内存是一种非常昂贵的资源,预计到 2025 年将达到服务器价值的 40% 以上。
继续阅读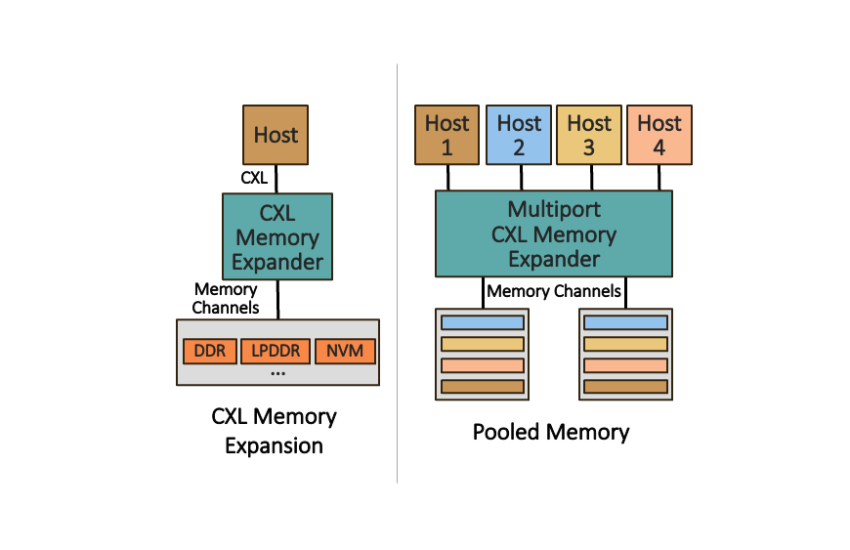
CXL 3.0允许每个主机支持多达16个加速器,使其成为用于GPU的标准一致性互连。它还增加了点对点(P2P)通信、多级交换和最多4,096个节点的结构。
继续阅读
三个季度前,我们曾经评测过Intel X710-T4四口10G base T的网卡,那时我们曾提到我们没办法在我们的评测中进行测试。
继续阅读
在五花八门的GPU和AI加速芯片产品背后,GPU服务器硬件设备究竟在沿着什么样的技术路线发展?本文抛砖引玉,谈谈对这一问题的看法。
继续阅读
Nvidia公司希望通过使数据中心的运行速度提高10倍,成本降低到原来的十分之一,彻底改变企业级计算领域。
继续阅读
Dell EMC推出了其最新的产品组合,包括第三代AMD EPYC “Milan”服务器和第三代Xeon可扩展(Ice Lake)服务器。
继续阅读