在单个GPU性能有限的情况下,将两个或多个GPU连接起来这种在当时看起来非常荒谬的想法竟然渐渐成为提升系统GPU性能的主流方法。
继续阅读
Google AI TPU
在单个GPU性能有限的情况下,将两个或多个GPU连接起来这种在当时看起来非常荒谬的想法竟然渐渐成为提升系统GPU性能的主流方法。
继续阅读
IBM的“北极”NorthPole是一种类脑芯片,我们需要先了解什么是类脑芯片。
继续阅读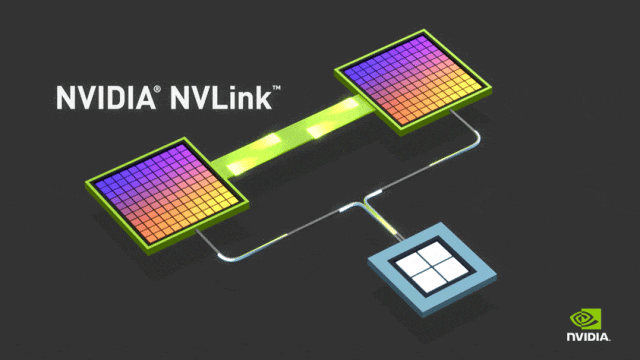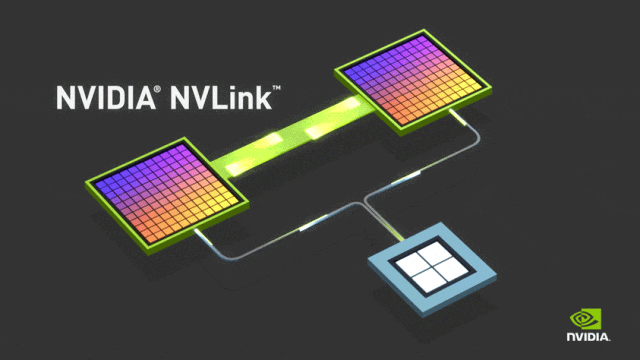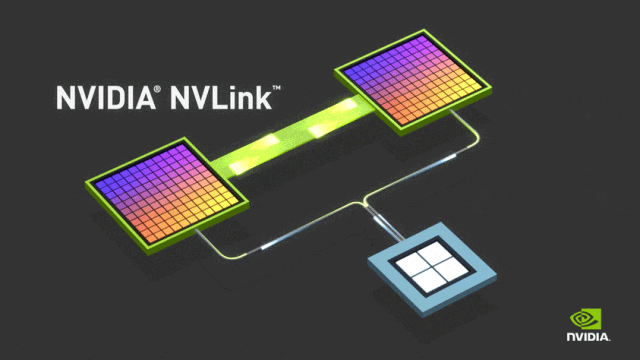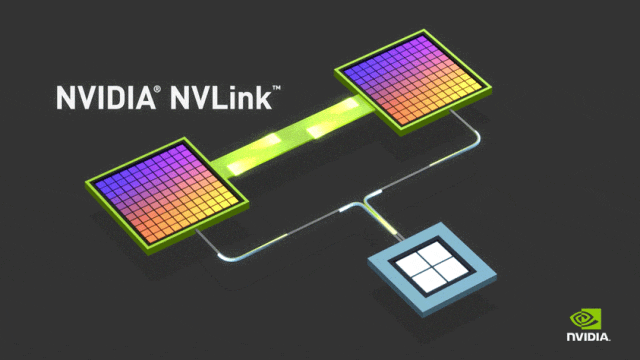
随着人工智能和图形处理需求的不断增长,多 GPU 并行计算已成为一种趋势。
继续阅读
Nvidia发布了一份财务报告,其中包含新的Nvidia芯片路线图,囊括了GPU、GPU以及交换ASIC芯片。
继续阅读
在Google I/O 2023活动中,Google软件产品组合中的生成式AI功能成为焦点,这一点毫不奇怪。
继续阅读
图形处理器(GPU,Graphic Processing Unit)是面向吞吐率设计、片上集成大量并行计算部件的处理器。2006年采用统一架构的GPU和使用高级语言编程的开发平台的出现,引发了GPU通用计算领域的迅猛发展。
继续阅读
HPC指的是在多台服务器上以高速并行方式执行复杂计算的能力。这些服务器的集合被称为集群,由数百甚至数千台计算服务器通过网络连接而成。
继续阅读
应该预先以整体性的方式来解决存储扩展问题。这包括容量、性能、网络硬件和数据传输协议。其中的关键点是确保充足的GPU资源,否则,训练和推理工作可能会失败。
继续阅读
NVLink的目标是突破PCIe接口的带宽瓶颈,提高GPU之间交换数据的效率。2016年发布的P100搭载了第一代NVLink,提供160GB/s的带宽,相当于当时PCIe 3.0 x16带宽的5倍。
继续阅读在生成式AI(GenAI)领域存在一个鲜为人知的问题,它可能会阻碍许多用户实现其目标:其IO模式可能会对传统存储系统造成巨大压力。
继续阅读