HDD的每TB带宽一直在下降。这迫使数据中心工程师通过将热(频繁访问的)数据转移到TLC闪存层或过度配置存储来满足其存储性能需求。
继续阅读
英特尔正式推出Gaudi 3,最强CPU同步亮相
英特尔今天正式推出了用于 AI 工作负载的 Gaudi 3 加速器。新处理器的速度比 Nvidia 广受欢迎的 H100 和 H200 GPU(用于 AI 和 HPC)要慢,因此英特尔将其 Gaudi 3 的成功押注于其较低的价格和较低的总拥有成本 (TCO)。
继续阅读Google AI TPU






英特尔今天正式推出了用于 AI 工作负载的 Gaudi 3 加速器。新处理器的速度比 Nvidia 广受欢迎的 H100 和 H200 GPU(用于 AI 和 HPC)要慢,因此英特尔将其 Gaudi 3 的成功押注于其较低的价格和较低的总拥有成本 (TCO)。
继续阅读
美光科技在2022年就宣布了在美国建造两个新晶圆工厂的计划,但当时并未明确指出具体的投产时间,仅表示将在十年内实现,随后的2023年,该公司通过一系列支出策略调整加快了这些工厂的建设进程。
继续阅读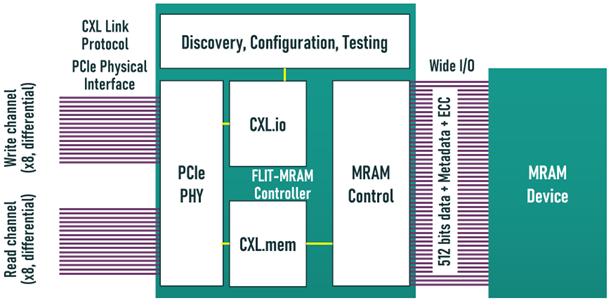
FLIT-MRAM通过利用日益普及的CXL基础设施,重新构思了DRAM解决方案的架构。将DRAM DDRx物理接口替换为CXL接口,使内存事务能够通过CXL的64字节FLIT有效负载与处理器的64字节缓存行匹配。
继续阅读
三星电子官方宣布,已经开始批量生产PM9E1,行业性能最快的PCIe 5.0 SSD,同时有着超大容量。
PM9E1采用了三星电子自研的5nm工艺主控方案,搭配第八代V-NAND闪存,容量可选512GB、1TB、2TB、4TB。
继续阅读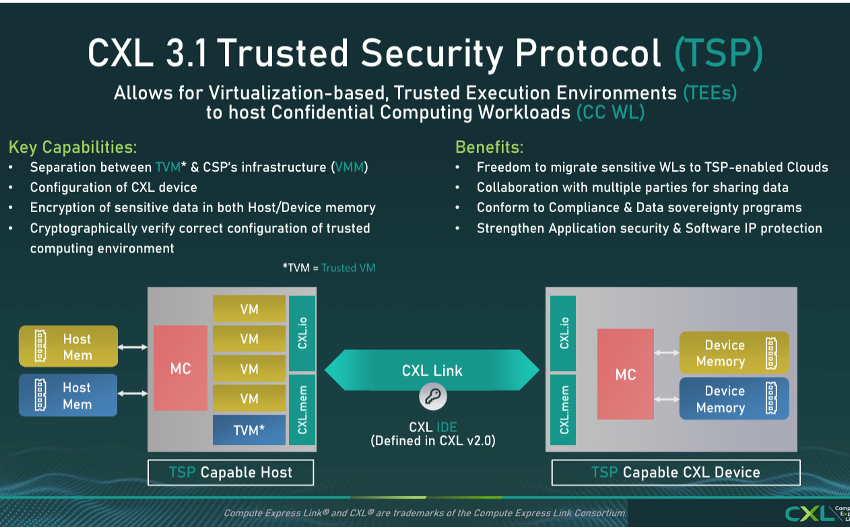
Compute Express Link建立在 PCI Express 基础上,几乎所有主要芯片公司都支持该技术。它用于通过串行通信连接 CPU、GPU、FPGA 和其他专用加速器,但它还允许跨设备池化内存,以提高资源利用率和高效利用率。
继续阅读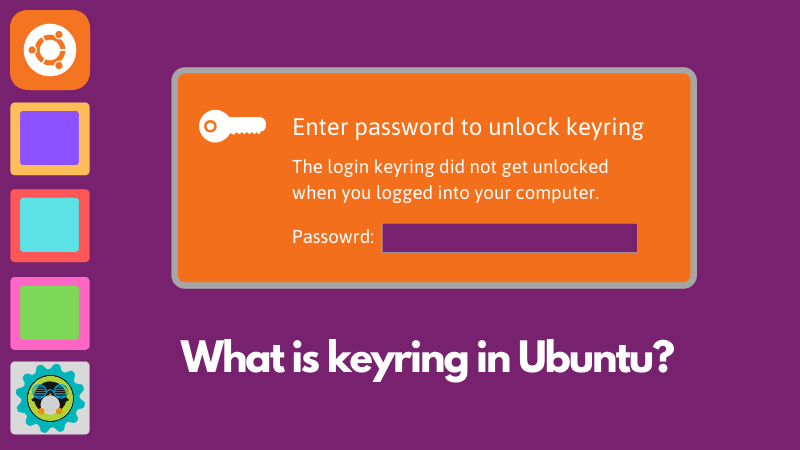
在Ubuntu系统上使用Microsoft Edge浏览器时,很多用户会遇到频繁的“输入密钥”的提示。
继续阅读
据《华尔街日报》援引知情人士消息,近日,高通已就收购事宜接洽英特尔。这将是近年来规模最大、影响最深远的交易之一。
继续阅读
美光科技宣布其第九代(G9)TLC NAND SSD开始量产,这是该行业的一个重要里程碑。G9 NAND具有3.6 GB/s的传输速度,为数据读取和写入提供了出色的带宽。
继续阅读
NVIDIA GH200 的独特之处在于其CPU与GPU的集成方式。它包含72个基于Arm v9架构的内核(Neoverse V2),并通过高速的NVLink-C2C接口将CPU与GPU紧密相连,提供了极高的带宽和性能。
继续阅读我们将深入探讨这些协议增强措施的具体细节,以及它们如何助力实现大规模、高效能的计算架构。
继续阅读