近日我有幸阅读了英特尔公司互联系统领域的权威人物Debendra Das Sharma撰写的一篇开创性文章——《Novel Composable and Scaleout Architectures Using Compute Express Link》。在这篇文章中,Debendra Das Sharma详尽地阐述了如何利用CXL(Compute Express Link)技术构建一个可横向扩展的可组合分离架构。众所周知,CXL协议涵盖了type1、type2、type3三种设备类型,而目前学术界和工业界的研究主要集中在如何利用CXL技术扩展系统的内存容量。
然而至今尚未有文献系统地探讨如何直接通过CXL技术在机架级别构建一个支持异构计算、内存和存储设备的池化系统。据我了解,现有的CXL协议在不进行任何修改和优化的情况下,似乎难以胜任这一重任。至少在性能和可扩展性方面,它与PCIe相比并没有展现出显著的优势。
Debendra Das Sharma凭借其卓越的技术洞察力和对CXL技术的深刻理解,提出了一系列在现有CXL协议基础上的增强措施。这些建议旨在提升协议的性能和扩展性,部分提议已经在最新的CXL 3.1规范中得到了采纳。这些改进不仅为CXL技术的发展提供了新的方向,也为构建下一代高性能计算系统提供了可能。
在接下来的内容中,我们将深入探讨这些协议增强措施的具体细节,以及它们如何助力实现大规模、高效能的计算架构。这不仅涉及到硬件层面的创新,也包括软件和系统设计的新思路。通过这些综合措施,我们有望打破现有的技术瓶颈,推动计算技术迈向一个新的高度。
背景知识
CXL是一个开放的行业标准互连,它在PCI-Express之上提供了缓存和内存语义。除了在主机处理器和加速器、智能网络接口卡以及内存扩展设备之间提供高带宽和低延迟的连接外,它还支持跨多个系统的资源共享池,实现可扩展、节能和成本效益高的计算。接下来会探讨使用CXL互连在机架级别及更高级别上搭建可组合和可扩展架构,以实现异构内存和异构计算资源的池化和共享。
PCIe是一个非一致性互连。PCIe设备一般使用DMA完成系统内存读写事务以非一致性方式访问系统内存。附加到PCIe设备的任何内存都在系统中作为不可缓存的内存映射I/O(MMIO)区域进行映射。CXL 1.0/1.1在PCIe基础设施之上增加了一致性和内存语义,以支持细粒度的协同异构处理以及满足新兴计算需求所需的内存带宽和容量扩展。英特尔捐赠了最初的CXL 1.0规范,并在2019年领导了CXL联盟的启动。CXL 1.0/1.1支持I/O(CXL.io)、一致性(CXL.cache)和内存(CXL.memory)协议之间的动态多路复用,如图1(b)所示。CXL基于内存加载-存储语义。它在中央处理单元(CPU(s))(主机处理器)和跨异构内存的CXL设备之间维护统一的、一致的内存空间,如图1(a)所示。
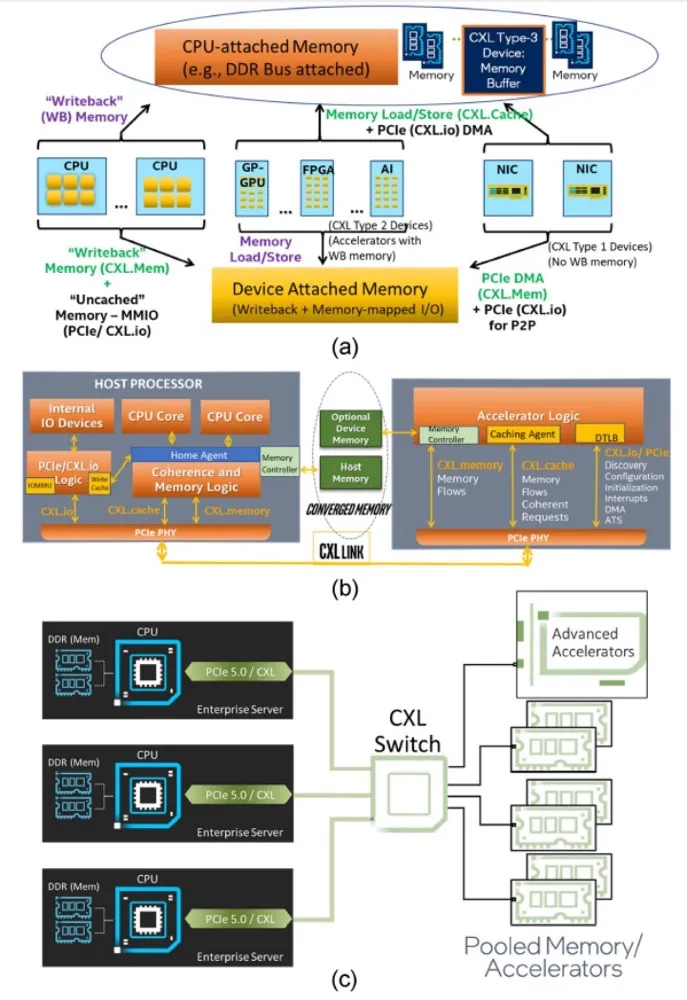
图 1. CXL 1.0和CXL 2.0的使用模式和协议。(a) 绿色文本显示了CXL 1.0启用的新系统能力。三种类型的CXL 1.0设备。(b) CXL在PCIe PHV上的三种协议的动态多路复用。(c) CXL 2.0的资源池化。
CXL类型1设备是加速器,例如使用一致性语义以及PCIe的DMA传输的智能NIC。CXL类型2设备是加速器,例如通用图形处理单元(GP-GPU)和现场可编程门阵列(FPGA),它们具有可以部分或全部映射到可缓存系统内存的本地内存。CXL类型3设备用于使用可能具有自己内存层次结构的异构内存进行内存带宽和容量扩展。
后面文章会展示如何开发商业上可行的可组合系统,在POD级别具有加载-存储语义,并继续向后兼容CXL的演进。
CXL 2.0引入了通过允许多个域对一个或多个池化设备进行加载-存储访问的内存和加速器的池化概念。这种池化能力可以提供更高的能效同时降低总拥有成本,因为各个服务器不必过度配置内存,因为它们可以依赖内存池来应对需求的临时激增。CXL 2.0支持扇出和池化、内存和加速器池化、热插拔管理和资源管理器的切换,同时完全向后兼容CXL 1.0/1.1。因此,CXL 2.0为CXL提供了一种扩展到机架级别低延迟互连的机制,具有加载-存储语义。
CXL协议概述
68字节的FLIT是CXL中传输的基本单位。CXL.io基于带有非一致性加载-存储和生产者-消费者排序语义的PCIe协议。CXL.cache 支持设备缓存数据,采用请求和响应协议。主机处理器管理修改、独占、共享、无效(MESI)一致性协议,根据需要部署SNOOP消息。每个方向上都有三种消息类别:请求(Req)、响应(Rsp)和数据。在设备到主机(D2H,上行)方向上,Req 包括读取(例如,Rd_Shared,RdOwn)和写入;相应的下行 H2D 响应是全局可观察性(GO)。H2D-Req 是SNOOP,导致 D2H 响应SNOOP(例如,RspI,RspSHitSE)。
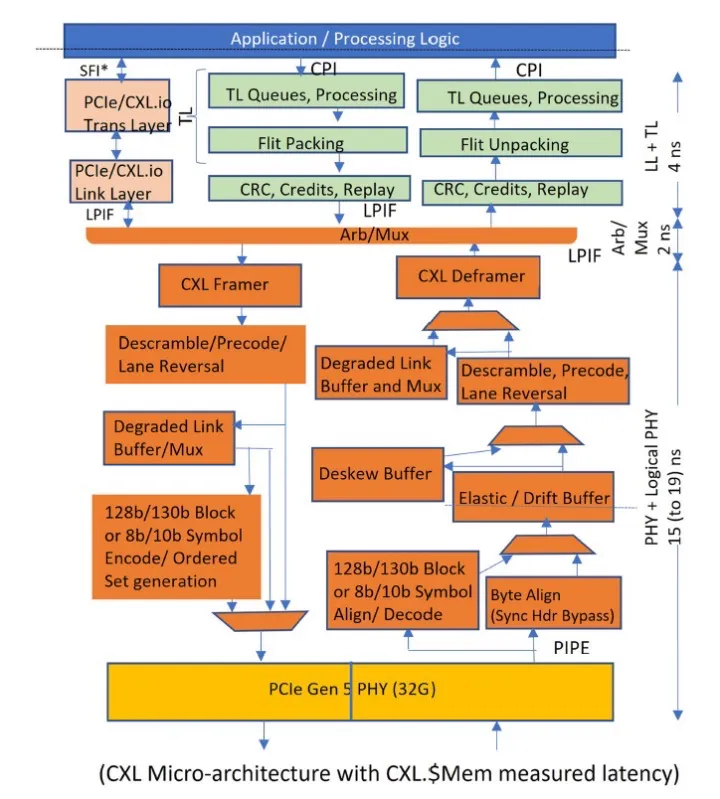
图 2. CXL 实现和测量的延迟
CXL.memory 支持类型2/3设备将其内存映射到系统的一致性内存中,这将被称为主机管理的设备内存(HDM)。它以缓存行粒度(64字节)在主机处理器(M)和类型2/3设备(S)之间传输内存加载和存储事务。请求从主机发送到设备在一个下游通道上:M2SReq(例如,读取请求),以及 M2S RwD(例如,写入)。响应从设备发送到主机在两个上行通道上:S2M NDR(无数据响应)和 S2M DRS(带数据的响应)。
CXL 实现和结果
CXL 1.0/1.1 在英特尔的 Sapphire Rapids (SPR) CPU 中实现,支持所有三种协议,符合 CXL 规范的要求。它已经通过在 32.0 GT/s 下运行的 x16 宽度的英特尔 FPGA 实现 CXL 进行了广泛测试。最后一级缓存(LLC)和窥探过滤器涵盖了 CXL设备中的缓存。无论是本地连接到 CPU 的双倍数据速率动态随机存取存储器(DDR)总线还是映射到系统地址空间的 CXL设备,内存都在 CPU 中的 Home Agent 的管辖范围内。
图 2 表示我们的 IP 级微架构块图。SERDES 引脚到应用层的总往返延迟目标是 21 或 25 纳秒,这取决于公共时钟模式是否开启。这符合 CXL 规范目标,即内存访问的引脚到引脚往返延迟为 80 纳秒,SNOOP的响应为 50 纳秒。因此,跨 CXL 链路的加载到使用延迟预计为 CXL.Mem 的大约 150-175 纳秒。
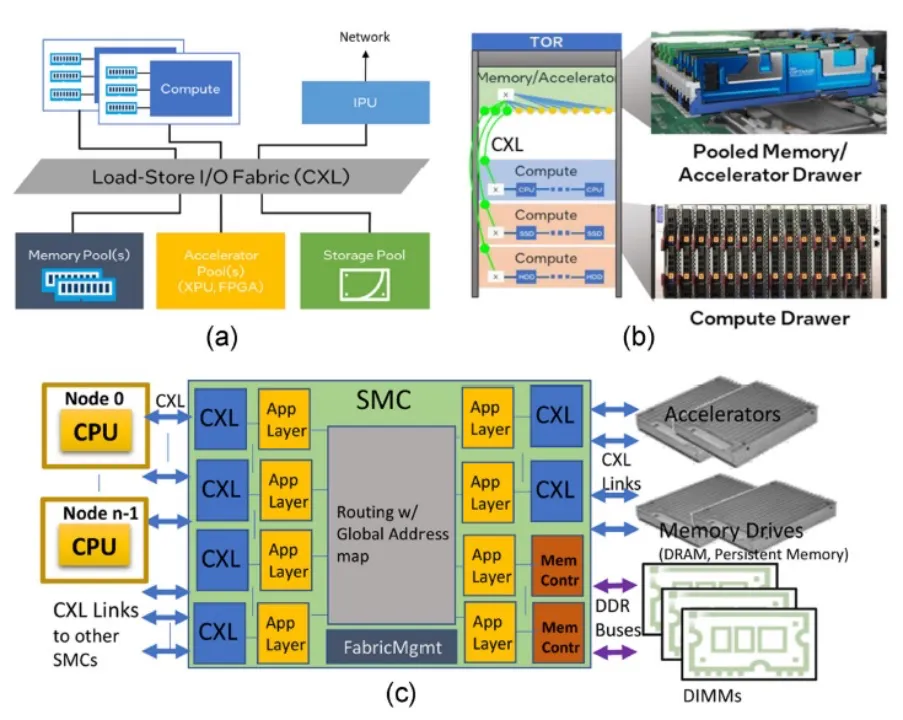
图3(a)和(b)展示了我们构建大型可组合服务器集群的架构愿景,这些服务器跨越一个或多个机架,使用CXL作为互连。每个机架抽屉可以是计算抽屉(抽屉可以理解为一个机架中有独立外壳的托盘),连接多个节点(服务器)与池化内存(包括双列内存模块、双列内存模块(DIMM)和CXL内存驱动器),和池化加速器。每个节点可能有自己的专用内存、加速器和其他I/O资源。一个抽屉也可以只由内存或加速器组成,这些可以是跨机架资源池的一部分。共享内存控制器(SMC)芯片提供CXL连接。SMC也可以本地托管DDR内存,如图3(c)所示。SMC之间的互连可以通过机架内的铜缆(1-2米)。或者使用光纤用于SMC之间的跨机架连接。
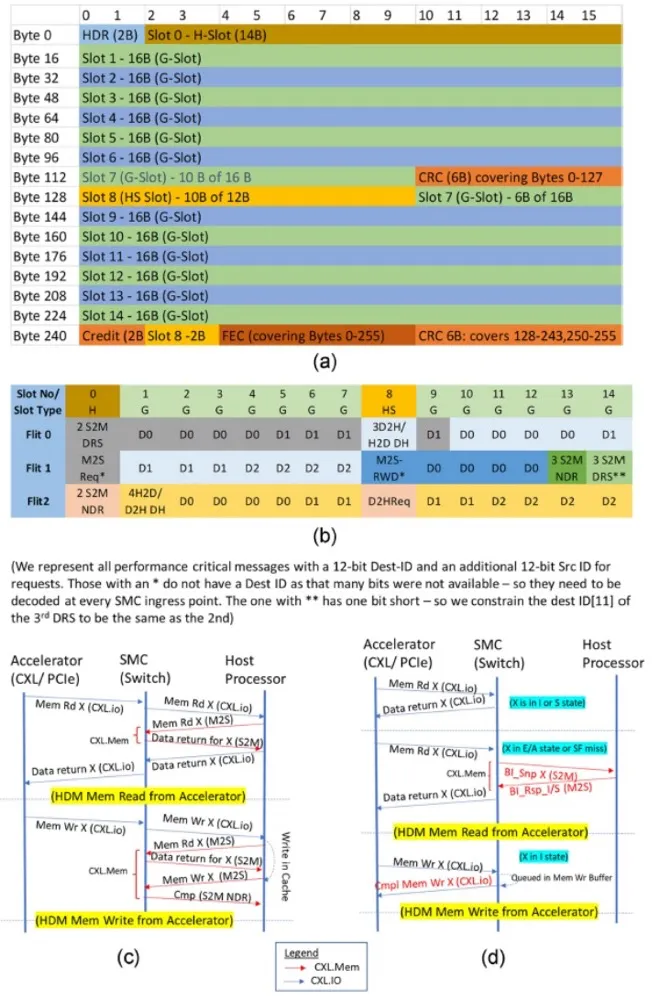
图 4. 延迟优化的FLIT布局,提出的CXLFLIT打包和CXL事务增强。(a) 128字节优化的FLIT布局。(b) 使用我们提出的可扩展性机制,在SMC-SMC链路中使用128字节LO FLIT的例子。(c) 现有的CXL(1.0,2.0)流程;所有HDM访问都通过主机处理器与HA进行。(d) 直接访问HDM内存的提出流程;新流程以红色文本显示。
CXL协议和能力增强
文中提出了几项CXL增强措施,以实现可组合和可扩展架构。这使得跨多个域共享和池化资源(例如,内存、加速器);每个域都是一个独立的服务器。可以构建跨机架的可组合系统,每个域都可以根据需要动态地从资源池中添加/移除资源。新的架构还通过使用共享内存、跨域中断、信号量和基于CXL的直接加载存储内存访问语义的消息传递,实现跨域的协同计算。
后面需要在不增加延迟惩罚的情况下将可扩展架构带宽翻倍。CXL 3.0规范采用了64-GT/s PAM-4信号与我们的128字节sub-FLIT机制(与CXL 2.0相比没有增加任何延迟)。图4(a)显示了不同slot的布局。通用(G)slot为16字节,可用于头和数据,而H/HS slot(14/12字节)仅用于头。
为了构建图3所示的大规模可扩展系统,即使存在多级SMC也需要有接近单节点性能的表现。文中方法适用于任何使用无死锁路由机制的拓扑结构,没有PCIe和CXL 1.0/2.0的树形拓扑限制。SMC之间的CXL链路需要是CXL 3.0协议加上这里讨论的增强功能,并支持每个CXL协议的上下游通道。
我们提议增强CXL 3.0的128字节延迟优化(LO)FLIT,使用12位端口ID号通过SMC路由。这比256字节的方法提供了更低的延迟和更高的带宽效率。端口ID号只需要唯一标识连接到SMC的主机CPU或CXL设备,允许多达4,096个主机CPU或设备(可以是PCIe/CXL 1.0/CXL 2.0/CXL 3.0)连接到任何SMC端口。为此,我们需要在每个头进入第一个SMC时添加12位目标端口ID(也称为Dest-ID)。对于请求,我们需要添加12位源端口ID(Src-ID),以便响应可以路由回源节点。当事务传递到CPU或设备并在出口SMC端口交付时,这些Dest-ID / Src-ID将被移除,并转换为标准PCIe/CXL 1.0/1.1/2.0/3.0格式,以便现有的CPU/设备可以与我们提出的架构一起工作,该架构仅将可组合性和可扩展性负担放在SMC上。CXL.Cache/Mem头有足够的备用位来适应这种扩展,并且仍然适合CXL3流量的任何slot。
我们已经确定了CXL 3.0规范中所有性能关键的头编码,如图4(b)所示(例如,一个G slot中的3个S2M NDR)。即使在每个事务中添加了额外的端口ID位,我们也可以容纳它们,包括每个slot有多个头的那些。有两个例外:1)有两个头(M2SReq,M2SRwD),由于没有足够的备用位,Dest-ID没有发送。因此,这两个需要在每个SMC进行目的ID查找(而不是在进入SMC复合体时一次)。我们认为,为了保留外部链路带宽而增加的查找逻辑带宽是一个合理的权衡。2)有一个实例,其中插槽中的第三个数据返回头(DRS)需要与第二个DRS具有相同的目标ID位。这也是一个合理的权衡,因为我们无法发送3个DRS(而是发送2个DRS)的唯一时间是如果有超过2,048个CPU/CXL设备,并且在一个重负载系统中我们无法调度两个具有相同Dest-ID的DRS。
通过这些提议的优化,对于CXL.Cache/CXL.Mem,现有的单一域与我们为大型可组合系统提出的多域支持之间没有效率损失。对于跨SMC链路的CXL.io访问,在SMC的初始入口点,目标端口ID生成并添加为事务层数据包(TLP)前缀,并适当转换为目标域的总线、设备和功能。TLP前缀的额外4个字节将对CXL.io带宽产生很小的影响。
为了在大型系统中扩展性能,我们还提出了新的CXL流程,其中一些已经被采用在CXL 3.0规范中。在CXL 1.0/CXL 2.0中,所有HDM访问都通过主机处理器进行,以解决缓存一致性,即使类型2/3设备可以通过SMC直接访问,如图4(a)所示。这导致链路带宽浪费和额外的延迟。我们提出直接点对点(p2p)访问HDM内存,我们在CXL.io中称之为“无序I/O”(UIO),类似于MMIO访问的点对点。我们在S2M中添加了一个新的回退使能窥探(“BI-Snp”)和相应的回退使能响应(“BI-Rsp”),以支持这种直接p2p HDM访问。这种方法保留了CXL的不对称性,因为主机处理器仍然协调一致性并解决可缓存访问的冲突。BI-Snp只启用设备端内存控制器支持直接点对点访问,类似于自CXL 1.0时代以来类型2设备已经具备的能力,而不会引入实现类型2设备的缓存语义和偏置翻转流程的复杂性。
类型2/3设备已经有一个目录,由两位存储元数据(MESI状态:I、S、E/A,其中A代表任何MESI状态)。接收到其HDM内存的直接UIO请求的类型2/3设备,如果可以在保持MESI一致性机制的同时本地服务事务[例如,如果状态是I/S,则为读取(写入)请求];否则,它将触发BI-Snp流程,如图4(b)所示,以通过主机CPU强制执行MESI一致性机制,然后完成请求。这些回退使能流程还使类型2设备能够部署一个窥探过滤器。BI流程是CXL.Mem中的一个单独消息类别,因为CXL.Mem不依赖于其他消息类别,并且CXL.Mem存在于类型3(和类型2)设备中。我们还提议为CXL.io UIO写事务添加一个可选的完成流程,如图4(b)所示,从而将生产者-消费者排序点移动到源,以实现CXL.io的多路径。
我们提议使用增强类型2/3设备在CPU和设备之间使用硬件强制缓存一致性共享内存。内存控制器可以在芯片上实现一个窥探过滤器,可选地由内存中的目录支持,或者仅仅是内存中的目录,其中它跟踪可能拥有缓存行的主机处理器(s)的端口ID,并根据需要向主机处理器(s)发送BI-Snp。这使得SMC能够在跨域的共享内存上强制执行缓存一致性。这种共享内存也可以用来跨域实现信号量。我们基于CXL.io(UIO)和非一致性CXL.Mem的节点间消息传递机制。
我们提议使用单根I/O虚拟化,为多个域中的CXL类型1/2和PCIe设备添加池化能力。在这种情况下,fabric管理器将负责设备。SMC将把所有配置请求转发给fabric管理器,该管理器将模拟配置访问并确保跨域的隔离。一个域只对其分配的设备功能(s)的内存空间有直接访问权,这是为了提供最佳性能所必需的。
SMC微架构
图3(c)显示了SMC芯片的块图,它支持连接到CXL节点(主机处理器或CXL设备)或其他SMC的CXL链路,以及连接到DRAM内存的DDR总线。CXL管理接口提供了分布式fabric管理功能,这些功能对于协调资源分配、控制池化、共享CXL设备的配置寄存器空间以及在SMC内部跨域设置公共数据结构是必需的。每个主机都有独立的系统地址空间视图。带有分布式fabric管理软件栈的SMC协调全局地址映射,如图5所示。因此,对从CXL节点的访问通过SMC内部的地址映射和路由逻辑进行适当的重映射。SMC内部数据路径和SMC链路中的事务头携带源和/或目标的12位端口ID进行路由。SMC需要在交付给CPU或设备时取下这些前缀、源/目标端口ID,并在完成时重新分配它。除了跨域的地址转换外,SMC在我们的提议架构中还提供对复制、邮箱、信号量和中断服务的支持。
性能指标
SMC之间的连通性 一个抽屉可以有一个或多个SMC。对于大规模扩展配置,我们期望每个独立链接是x4@64.0GT/s,每个方向32 GB/s。拥有192个通道或48个链接,每个SMC可以连接到机架中所有16个独立服务器和16个池化设备,另外16个可以用于连接机架内/跨机架的其他SMC。因此,使用两个级别的SMC可以在16个机架之间实现连通性。
用于I/O一致性访问和图5中描述的跨域消息传递,可以部署CXL.io或CXL.Mem机制。由于带宽效率CXL.io更高,并且它不会消耗连接到SMC(s)的系统内存来备份消息传递空间,我们建议仅使用CXL.io进行跨域消息传递,以获得性能、实现简单性和成本效益。表1(a)和(b)总结了我们使用CXL.io的带宽结果。
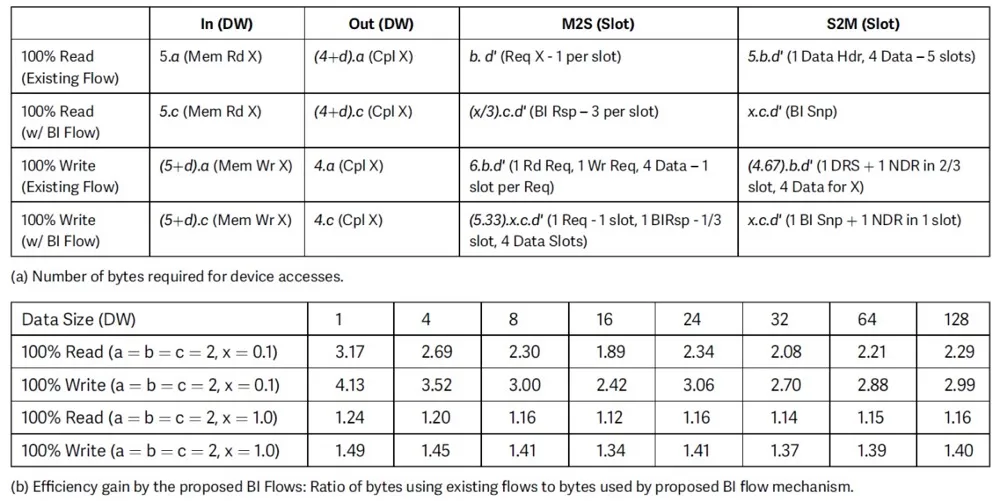
表1 架构的链路效率
如上所述,我们提议通过直接点对点(包括不涉及缓存的DMA和跨域消息)绕过主机处理器进行CXL.io访问。预期绝大多数这些访问不会引发BI-Snp机制来强制一致性。这有助于提高链路效率以及减轻主机处理器链路的拥塞。如表1(b)所示,即使在所有访问都引发BI-Snp的极端情况下,这种机制的效率增益也是显著的,因为这比跨链路的多缓存行传输更好。
根据我们在“带有CXL的可组合、可扩展机架级架构”部分中介绍的结果,CXL堆栈的Tx+Rx路径为25纳秒。即使增加额外的15纳秒用于内部延迟,如排队/地址查找/仲裁/传播延迟等,每次通过SMC的跳转少于40纳秒。这使得两次SMC跳转对于内存访问非常可行。表2总结了我们基于在实现CXL和详细微架构SMC方面的工作经验对各种访问的估计。
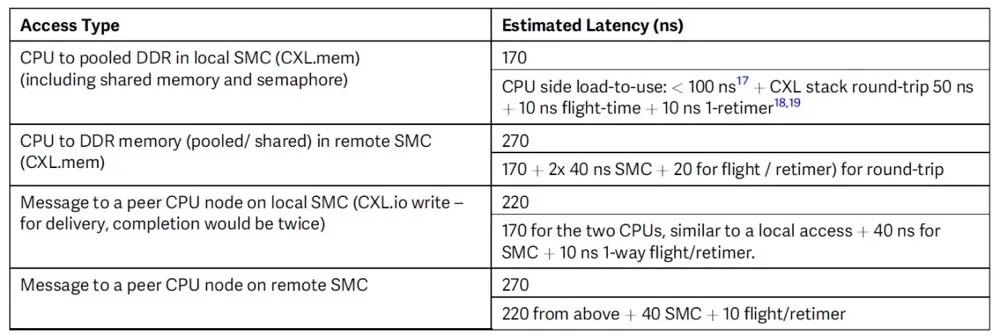
表2 架构的延迟估计
结论
CXL技术由于在成熟稳定的PCIe基础设施上实现低延迟缓存和内存语义的简便性而在行业中获得了广泛的关注。CXL可以进一步增强和部署,以跨越多个机架,为多种应用提供高可靠性和低延迟的加载-存储访问。通过我们提出的方法,我们期望实现构建跨越机架和数据中心的可组合和可扩展系统的愿景,从而实现能效性能,并带来显著的总拥有成本优势。







