
英特尔今天正式推出了用于 AI 工作负载的 Gaudi 3 加速器。新处理器的速度比 Nvidia 广受欢迎的 H100 和 H200 GPU(用于 AI 和 HPC)要慢,因此英特尔将其 Gaudi 3 的成功押注于其较低的价格和较低的总拥有成本 (TCO)。
英特尔的 Gaudi 3 处理器使用两个芯片组,包含 64 个张量处理器核心(TPC,带有 FP32 累加器的 256×256 MAC 结构)、八个矩阵乘法引擎(MME,256 位宽矢量处理器)和 96MB 片上 SRAM 缓存,带宽为 19.2 TB/s。此外,Gaudi 3 集成了 24 个 200 GbE 网络接口和 14 个媒体引擎,后者能够处理 H.265、H.264、JPEG 和 VP9,以支持视觉处理。该处理器配备 8 个内存堆栈中的 128GB HBM2E 内存,可提供 3.67 TB/s 的巨大带宽。
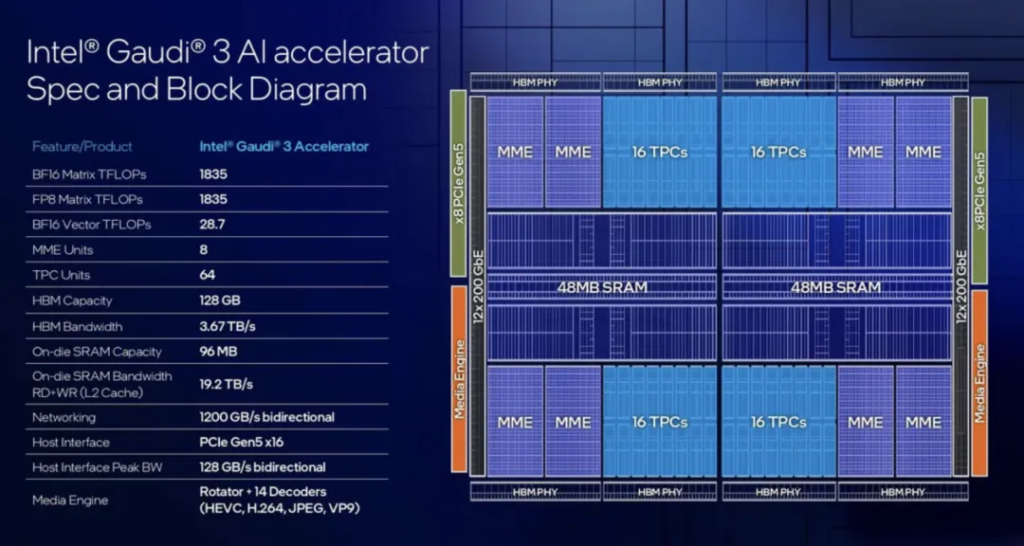
与拥有 24 个 TPC、两个 MME 和 96GB HBM2E 内存的Gaudi 2相比 ,英特尔的 Gaudi 3 有了巨大的改进。不过,英特尔似乎简化了 TPC 和 MME,因为 Gaudi 3 处理器仅支持 FP8 矩阵运算以及 BFloat16 矩阵和矢量运算(即不再支持 FP32、TF32 和 FP16)。

在性能方面,英特尔表示,Gaudi 3 可以提供高达 1856 BF16/FP8 矩阵 TFLOPS 以及高达 28.7 BF16 矢量 TFLOPS,TDP 约为 600W。与 Nvidia 的 H100 相比,至少在纸面上,Gaudi 3 的 BF16 矩阵性能略低(1,856 vs 1,979 TFLOPS),FP8 矩阵性能低两倍(1,856 vs 3,958 TFLOPS),BF16 矢量性能明显较低(28.7 vs 1,979 TFLOPS)。

比原始规格更重要的是 Gaudi 3 的实际性能。它需要与 AMD 的 Instinct MI300 系列以及 Nvidia 的 H100 和 B100/B200 处理器竞争。这还有待观察,因为它在很大程度上取决于软件和其他因素。目前,英特尔展示了一些幻灯片,声称 Gaudi 3 与 Nvidia 的 H100 相比具有显着的性价比优势。
今年早些时候,英特尔表示基于八个 Gaudi 3 处理器的加速器套件 售价为 125,000 美元,这意味着每个处理器售价约为 15,625 美元。相比之下,Nvidia H100 卡目前的售价为 30,678 美元,因此英特尔确实计划在价格上比其竞争对手更具优势。然而,由于基于 Blackwell 的 B100/B200 GPU 可能提供巨大的性能优势,这家蓝色公司是否能够保持相对于竞争对手的优势还有待观察。
英特尔执行副总裁兼数据中心和人工智能事业部总经理 Justin Hotard 表示:“对人工智能的需求正在推动数据中心发生巨大转变,业界要求在硬件、软件和开发工具方面做出选择。随着我们推出配备 P 核的 Xeon 6 和 Gaudi 3 AI 加速器,英特尔正在建立一个开放的生态系统,使我们的客户能够以更高的性能、效率和安全性实施所有工作负载。”

英特尔的 Gaudi 3 AI 加速器将通过 IBM Cloud 和英特尔 Tiber 开发者云提供。此外,基于英特尔 Xeon 6 和 Gaudi 3 的系统将于第四季度从戴尔、HPE 和超微全面上市,戴尔和超微的系统将于 10 月出货,超微的设备将于 12 月出货。
向数据中心推出“Granite Rapids” Xeon 6
英特尔谈论其“Granite Rapids” Xeon 6 处理器已经很长时间了,人们很容易忘记它们尚未正式发布。
但今天,“Granite Rapids”服务器 CPU 系列的高端产品首次亮相,而这比 AMD 普遍预计发布其“Turin”第五代 Epyc 处理器早了几个星期。虽然我们认为 AMD 将继续扩大市场份额,但 Granite Rapids 加上今年 6 月发布的“Sierra Forest”Xeon 6 芯片的组合,即使不能扭转趋势,也将帮助英特尔减缓数据中心 CPU 市场份额的损失。
老实说,考虑到 AMD 与台湾半导体制造公司合作而仍然在芯片制造工艺上保持领先地位,以及英特尔自身在代工业务方面遇到的困境,这是最好的结果了。
正如我们多次指出的那样,有设计胜利和供应胜利,虽然前几代 Xeon 显然只是供应胜利,但可以公平地说,Sierra Forest 和 Granite Rapids 都开始获得一些设计胜利,即使英特尔的销售仍然主要归功于供应胜利。
Xeon 6 芯片的 E 核和 P 核变体的芯片封装和架构(在英特尔术语中是“效率”和“性能”的缩写)早在 Hot Chips 2023 上就已披露。我们今年夏天对 Sierra Forest 的深入研究,英特尔为服务器 CPU 刀战带来了大分叉,填补了 Xeon 6 技术和战略中的许多空白。因此,我们不会大惊小怪,我们将在明年年初直接进入 Granite Rapids 阵容和未来 Xeon 6 芯片的路线图。
当然,在这篇最初的报道之后,我们将对 Granite Rapids 进行架构深入研究。我们将回顾英特尔所做的竞争分析,将 Granite Rapids 与2022 年 11 月推出的当前第四代“Genoa”Epyc 9004 芯片、2023 年 6 月推出的“Bergamo”Epyc 97X4 芯片(其核心数量与 Sierra Forest 一样增加)以及即将推出的“Turin”Epycs 进行对比。
Granite Rapids 处理器基于“Redwood Cove”P 核心,是 Sapphire Rapids 和 Emerald Rapids 中使用的“Golden Cove”核心的更新版。与 Golden Cove 核心相比,Redwood Cove 核心在整数工作负载上每时钟指令数 (IPC) 增加了 5% 到 7%,虽然只是名义上的增加,但仍然是增加。我们取中间值 6% 的 IPC 来与前几代 Xeon 进行比较。我们被警告不要过分关注这个常用指标。(顺便说一句,我们并不认为我们会关注这个指标,但它确实有用。)
“我最近确实做了一个小演讲,说人们过于关注 IPC,”英特尔高级研究员兼 Xeon 6 产品线首席架构师 Ronak Singhal 告诉The Next Platform。“具体来说,如果我的内部团队来找我,为我提供一个 IPC 为 5% 的核心和一个 IPC 为 15% 的核心,哪个对 Xeon 更有利?答案是这取决于其他参数,特别是功率。如果 5% IPC 选项使我多花费 0% 的功率,但 15% IPC 选项使我多花费 30% 的功率,那么在功率受限的世界中,这两个选项平均而言大致相同,而且其中一个可能不那么复杂。所以,虽然每个人都喜欢讨论 IPC,但我们真正需要谈论的是功率受限下的性能。我之所以这么说,是因为 Granite Rapids 的核心在很多方面更注重降低功率,而不是提高 IPC。”
很合理,而且很有道理。从这个角度来看。如果你使用两个 Emerald Rapids CPU(即四个芯片),并将它们保持在英特尔 7(实际上是 10 纳米)上,那么你将创建一个 112 核计算综合体,其重量将超过 700 瓦,并且插槽尺寸将是原来的两倍。如果你使用相同的两个 Emerald Rapids CPU(同样是四个芯片),并将它们缩小到英特尔 3(有人说类似于 5 纳米工艺,其他人说更像 3 纳米工艺),你可以在大致相同的功率下将性能提高一倍,这仅仅是由于工艺缩小,但它可能再次接近 700 瓦,这是原始芯片的 2 倍。
然而,对于 Granite Rapids,英特尔将核心数量从之前两款 P 核处理器的 56 个核心提升至 120 个,增加了 2.3 倍,而顶部部分的功率仅增加至 500 瓦,仅增加了 1.4 倍。
当然,情况要复杂一些,因为 Granite Rapids 和 Sierra Forrest 在封装中的多个芯片上混合使用了英特尔 3 和英特尔 7 工艺。在 Sapphire Rapids 和 Emerald Rapids 中,英特尔将 I/O 和内存控制器与计算核心放在同一个芯片上。但在 Sierra Forest 和 Granite Rapids 中,I/O 和内存芯片与计算核心分离,并在不同的工艺中实现,如下所示:
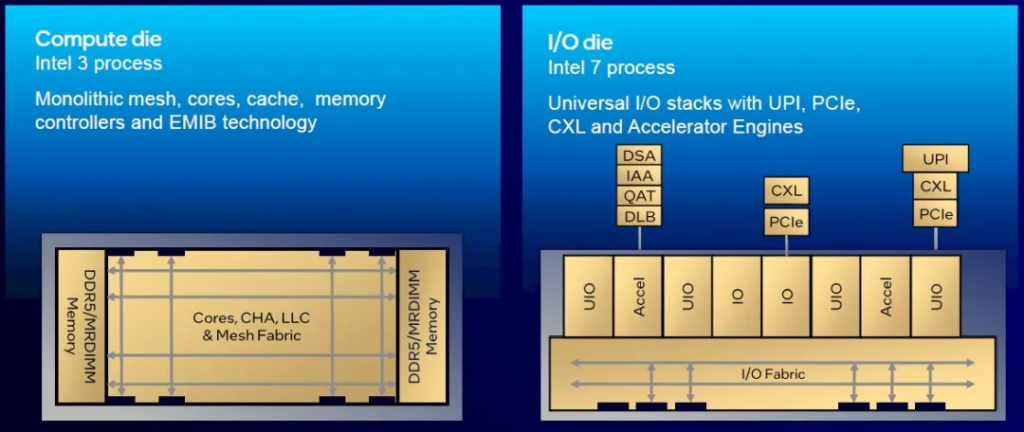
Xeon 6 系列中有四种不同的 P 核计算芯片和 I/O 芯片组合,其中一种——顶级超核心数 (UCC) 变体——于今天推出。
Granite Rapids Xeon 6 变体具有较少的计算块数量(两个用于极端核心数 (XCC) 变体或一个用于高核心数 (HCC) 变体),以及一个具有较小计算块以及两个 I/O 芯片的变体,称为低核心数 (LCC),将于 2025 年的某个时候问世。
核心芯片封装如下:

今天发布的 Granite Rapids UCC 套件被称为 Xeon 6 6900P,它包括最高运行速度为 6.4 GHz 的 DDR5 内存和可将其推高至 8.8 GHz 的多路复用列 (MRDIMM) 内存。得益于两个 I/O 芯片,插槽可以跨 UCC、XCC、HCC 和 LCC 进行配置,并且允许任何这些芯片直接插入任何“Birch Stream”平台,该平台还支持 Sierra Forest 及其后续产品“Clearwater Forest”,该产品将于明年某个时候采用英特尔 18A(1.8 纳米)工艺推出。
Granite Rapids 套件支持最多 96 条 PCI-Express 5.0 通道,还可运行 CXL 2.0 一致性内存协议。该套件还具有高达 504 MB 的 L3 缓存,与英特尔通常的缓存相比,这非常大。
据我们所知,今天发布的 Granite Rapids 芯片没有支持四路和八路服务器的变体,这很遗憾。Sierra Forest Xeon 6 也是如此(考虑到它的用例,我们预计会支持),2023 年 12 月推出的上一代第五代“Emerald Rapids”Xeon SP v5 芯片也是如此,后者是一条更广泛的 Xeon SP 产品线,并且可能具有扩展的 NUMA 集群。您必须从 2023 年 1 月开始使用“Sapphire Rapids”Xeon SP v4 芯片才能获得英特尔支持四路和八路 NUMA 的 CPU。
顺便说一句,由于有六个 UltraPath Interconnect NUMA 链接以 24 GT/秒的速度运行,因此英特尔及其 OEM 和 ODM 合作伙伴没有技术原因不能使用这些 Granite Rapids 芯片制造具有两个以上插槽的 NUMA 机器。这肯定是足够的动力和足够的链接。
英特尔尚未透露 Granite Rapids 计算模块的内核数量,但根据您认为英特尔的英特尔 3 工艺产量,您可以合理地猜测 48 个内核或 45 个内核。对于具有 128 个内核的 UCC 变体,您必须在这些芯片上产生奇数才能使其发挥作用。(我们讨厌不均匀分布的情况,甚至更糟的是,不除以 2。)每个计算芯片都有四个 DDR5 内存控制器,总共十二个,就像当今大多数高端 CPU 一样,使用 MRDIMM 内存,Granite Rapids 上的有效带宽比 Emerald Rapids 上的有效带宽高 2.3 倍。
下面是一张很好的摘要图表,显示了 Xeon 6 P 核和 E 核变体之间的差异:
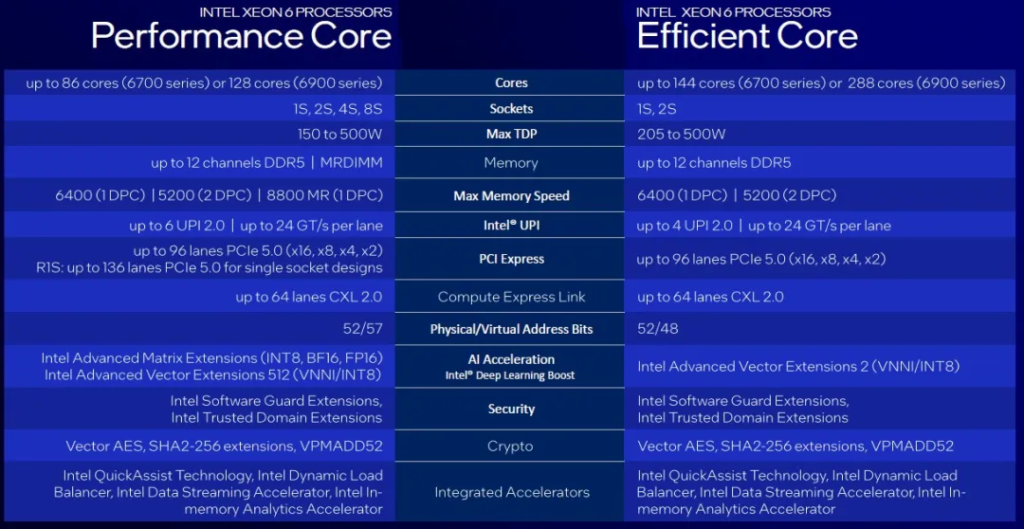
尽管 Xeon 6 处理器的 P 核和 E 核版本使用相同的 I/O 芯片,但显然并非所有功能都在 E 核版本中激活。您会注意到,对于单插槽设计,P 核 6700 系列芯片不知何故提供了 136 个 PCI-Express 5.0 通道。E 核芯片上的虚拟内存寻址要低得多,这是有道理的,因为它们只会在具有一个或两个插槽的机器中使用,而不是多达八个或更多插槽。E 核具有不同的矢量数学单元,只有 P 核具有 AMX 矩阵单元。图表显示即将推出支持四个和八个插槽的 P 核 Xeon 6 芯片。
这让我们看到了 Granite Rapids 的 SKU 堆栈,它相当适中,只有 5 种不同的变体。看一看:
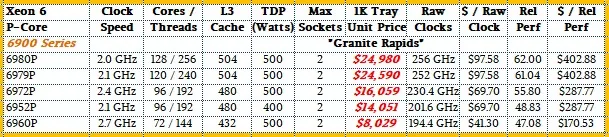
辛加尔在发布会前的简报中表示,谷歌和亚马逊网络服务公司正在为其产品系列获取定制的 Xeon 6 处理器,我们想象其他公司也是如此。
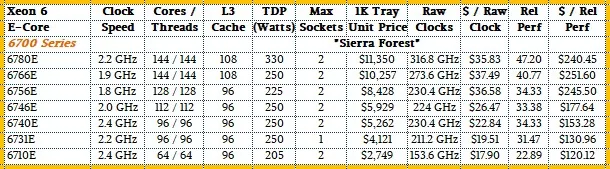
为了便于比较,下面是 Sierra Forest Xeon 6 SKU 的表格,同样只有 7 种不同型号:
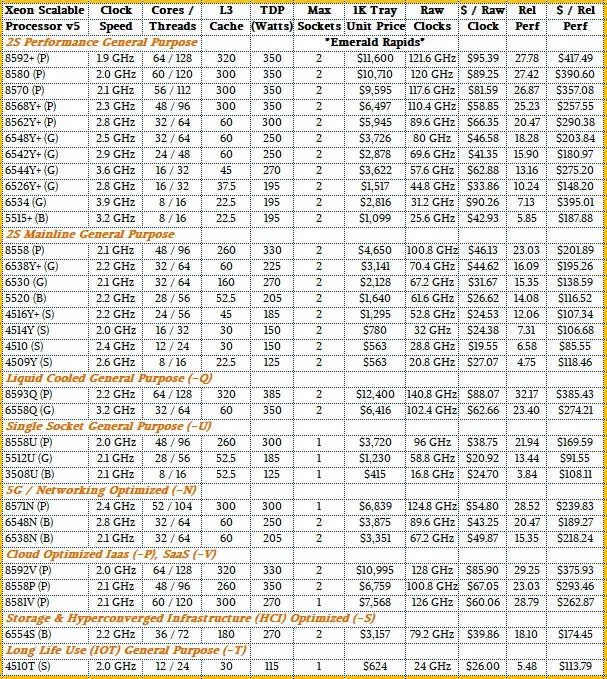
以下是去年 Emerald Rapids SKU 的详细表格:
与往常一样,我们的相对性能数据是根据任何特定型号的 Xeon 与 2009 年的“Nehalem”Xeon E5540 处理器的性能来计算的,后者拥有四个内核,运行速度为 2.53 GHz,8 MB L3 缓存,散热能力为 80 瓦。为了计算相对性能,我们将每个型号的内核数量乘以时钟速度,再乘以每一代 IPC 的累计增量。
考虑到我们为此目的而精心跟踪的累积 IPC,Redwood Cove 核心的整数性能比 15 年前的 Nehalem 核心高出 2.42 倍。这是相当不错的架构增强。与 Nehalem 相比,Granite Rapids 的核心数量增加了 32 倍,但所有这些核心的时钟速度都下降了 21%,而功耗却增加了 6.25 倍。
这就是芯片业务。
您会注意到上面的 Granite Rapids 表中还有一件重要的事情:价格以粗体红色斜体显示。这意味着英特尔没有公布 Granite Rapids Xeon 6 芯片的价格。我们显然不赞成这种做法。价格表提供了一个上限,人们可以在此基础上进行谈判,如果数量足够,他们肯定会这样做。
大自然厌恶真空,我们的孩子也是如此,因此我们根据以往的 Xeon SP 定价,尽最大努力估算了 Granite Rapids 芯片的价格。我们认为这些是英特尔在 Xeon 系列中推出的最昂贵的数据中心 CPU。(Itanium 不算,它不一样。)如果您知道价格是多少,请分享,我们也会分享。







