
谷歌旗下的Deepmind日前发布博客直言,我们(指代Deepmind,下同)的人工智能方法加速并优化了芯片设计,其superhuman chip layouts已应用于世界各地的硬件。2020 年,我们发布了一份预印本《使用深度强化学习的芯片布局》,介绍了我们用于设计芯片布局的新颖强化学习方法,后来我们在《自然》杂志上发表并开源了该方法。
今天,我们发表了一篇《自然》附录,详细介绍了我们的方法及其对芯片设计领域的影响。我们还发布了一个预先训练的检查点,分享了模型权重并宣布了它的名字:AlphaChip。
计算机芯片推动了人工智能 (AI) 的显著进步,AlphaChip 则利用人工智能来加速和优化芯片设计,以此回报人工智能。这种方法已被用于设计谷歌定制 AI 加速器张量处理单元(TPU) 的最近三代superhuman chip layouts。
AlphaChip 是首批用于解决实际工程问题的强化学习方法之一。它可在数小时内生成超人或同类芯片布局,而无需耗费数周或数月的人力,其布局已应用于全球各地的芯片,从数据中心到手机。
“AlphaChip 的突破性 AI 方法彻底改变了芯片设计的一个关键阶段。”联发科高管认为。
AlphaChip 的工作原理
设计芯片布局并非易事。计算机芯片由许多相互连接的块组成,这些块具有多层电路元件,所有元件都通过极细的导线连接。此外,还有很多复杂且相互交织的设计约束,必须同时满足所有约束。由于其复杂性,芯片设计师们在 60 多年来一直在努力实现芯片布局规划过程的自动化。
与学习掌握围棋、国际象棋和将棋游戏的AlphaGo和AlphaZero类似,我们构建了 AlphaChip,将芯片布局规划视为一种游戏。
AlphaChip 从空白网格开始,一次放置一个电路元件,直到完成所有元件的放置。然后根据最终布局的质量获得奖励。一种新颖的“基于边缘”图形神经网络使 AlphaChip 能够学习互连芯片元件之间的关系,并在整个芯片中进行推广,让 AlphaChip 在设计每个布局时都能不断改进。
使用 AI 设计谷歌的 AI 加速器芯片
AlphaChip 自 2020 年发布以来,已经生成了谷歌每一代 TPU 所使用的superhuman chip layouts。这些芯片使得大规模扩展基于谷歌Transformer架构的 AI 模型成为可能。
TPU 是我们强大的生成式 AI 系统的核心,从大型语言模型(如Gemini)到图像和视频生成器Imagen和Veo。这些 AI 加速器也是 Google AI 服务的核心,可通过 Google Cloud 供外部用户使用。
为了设计 TPU 布局,AlphaChip 首先在前几代的各种芯片块上进行练习,例如片上和芯片间网络块、内存控制器和数据传输缓冲区。这个过程称为预训练。然后我们在当前的 TPU 块上运行 AlphaChip 以生成高质量的布局。与之前的方法不同,AlphaChip 解决了更多芯片布局任务实例,因此变得更好、更快,就像人类专家所做的那样。
随着每一代新 TPU(包括我们最新的Trillium(第 6 代))的推出,AlphaChip 设计了更好的芯片布局并提供了更多的整体平面图,从而加快了设计周期并产生了性能更高的芯片。
AlphaChip 的广泛影响
AlphaChip 的影响可以从其在 Alphabet、研究界和芯片设计行业的应用中看出。除了设计 TPU 等专用 AI 加速器外,AlphaChip 还为 Alphabet 的其他芯片生成布局,例如Google Axion 处理器,这是我们首款基于 Arm 的通用数据中心 CPU。
外部组织也在采用和开发 AlphaChip。例如,全球顶级芯片设计公司之一联发科扩展了 AlphaChip,以加速其最先进芯片(如三星手机使用的Dimensity Flagship 5G)的开发,同时提高了功耗、性能和芯片面积。
AlphaChip引发了芯片设计人工智能研究的爆炸式增长,并扩展到芯片设计的其他关键阶段,例如逻辑综合和宏选择。
“AlphaChip 启发了芯片设计强化学习的全新研究方向,涵盖了从逻辑综合到布局规划、时序优化等设计流程。”纽约大学坦登工程学院 Siddharth Garg 教授表示。
创造未来的芯片
我们相信 AlphaChip 有潜力优化芯片设计周期的每个阶段,从计算机架构到制造,并将芯片设计转变为智能手机、医疗设备、农业传感器等日常设备中的定制硬件。
AlphaChip 的未来版本目前正在开发中,我们期待与社区合作,继续革新这一领域,创造一个芯片更快、更便宜、更节能的未来。
附录:快速芯片设计的图形布局方法
2020年,我们推出了一种能够生成超人芯片布局的深度强化学习方法。今天,我们给这种方法起了一个名字:AlphaChip。
AlphaChip是首批用于解决实际工程问题的强化学习方法之一,它的发布引发了芯片设计人工智能研究的爆炸式增长。然而,正如 Sutton 的《The Bitter Lesson》 中所描述的那样,人们往往不愿意接受将机器学习应用到新的领域,最终这导致了我们工作中的一些混乱,我们将在下面讨论这些问题。在本附录的最后,我们为感兴趣的读者提供了一些影响深远的部署示例。
预训练
与之前的方法不同,AlphaChip 是一种基于学习的方法,这意味着随着它解决更多芯片放置问题实例,它会变得更好、更快。这种预训练显著提高了它的速度、可靠性和放置质量,正如《自然》杂志的原始文章和 ISPD 2022 的后续研究中所讨论的那样。顺便说一句,预训练还催生了 Gemini 和 ChatGPT 等大型语言模型的惊人能力(“P”代表“预训练”)。
自发表以来,我们已开源一个软件存储库,以完全重现我们论文中描述的方法。外部研究人员可以使用此存储库在各种芯片块上进行预训练,然后将预训练模型应用于新块,就像我们在原始论文中所做的那样。作为本附录的一部分,我们还发布了在 TPU 块上预训练的模型检查点。但是,为了获得最佳效果,我们继续建议开发人员在自己的分发块上进行预训练,并提供有关如何使用我们的开源存储库进行预训练的教程。
显然,不进行任何预训练就会破坏我们方法的学习方面,因为这样就会失去从先前经验中学习的能力。
训练和计算资源
随着强化学习代理(或任何机器学习模型)的训练,其损失通常会减少,最终趋于稳定,代表“收敛”——模型已经了解了它所执行任务的所有知识。训练收敛是机器学习的标准做法,如果做不到这一点,可能会损害性能。
我们的方法的性能会随着所应用的计算资源而扩展,我们在 ISPD 2022 论文中进一步探讨了这一特性。正如我们在《自然》杂志上的论文所述,在对特定块进行微调时,我们使用了 16 个工作器,每个工作器由 1 个 GPU 和 32 个 RL 环境组成,通过多处理共享 10 个 CPU。使用较少的计算资源可能会损害性能,或者需要运行更长时间才能实现相同(或更差)的性能。
初始放置
在运行我们在《自然》杂志上评估的方法之前,我们利用物理综合(芯片设计流程的前一步)的近似初始布局来解决 hMETIS 中标准单元簇大小的不平衡问题。RL 代理无法访问此初始布局,也不会放置标准单元。
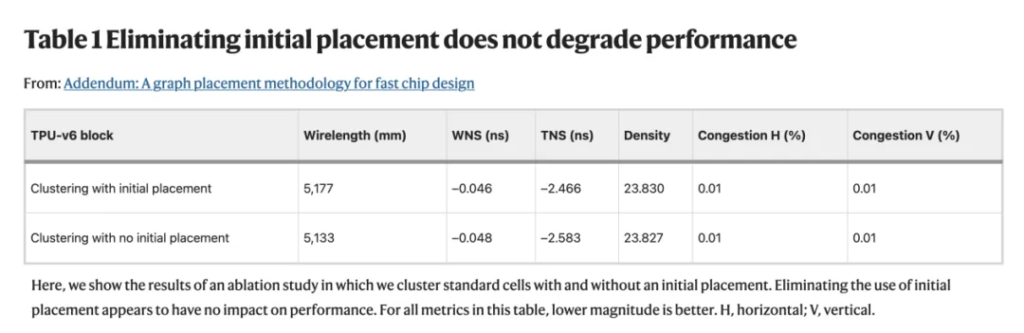
即便如此,我们还是进行了一项消融研究,消除了任何初始放置的使用,并且没有观察到性能下降(见表1)。具体来说,我们跳过了集群重新平衡步骤,而是将 hMETIS 的集群不平衡参数降低到最低设置(UBfactor = 1),这导致 hMETIS 生成更平衡的集群。
该辅助预处理步骤已于 2022 年 6 月 10 日起记录并开源,但似乎没有必要。
基准
在我们的《自然》论文中,我们报告了采用 10 nm 以下技术节点大小的 TPU 块的结果。这种技术节点大小是现代芯片的典型特征,但许多学术论文报告了较旧技术节点大小(如 45 nm 或 12 nm)的结果。从物理设计的角度来看,采用较旧技术节点大小的芯片存在很大差异(例如,在 10 nm 以下,通常使用多重图案化,导致在较低密度下出现布线拥塞问题)。因此,对于较旧的技术节点大小,AlphaChip 可能会受益于对其奖励函数的调整。我们欢迎社区做出贡献,为较旧的技术节点大小开发更相关的成本函数。
对本文的澄清
为了进一步减少混淆,我们在原始论文中添加了两个澄清句子和两处小编辑:
在图 4 的标题中,我们指定了超参数设置:“密度权重设置为 0.1,拥塞权重设置为 0”。根据我们的经验,我们发现预训练对所有超参数设置都有效。
在“标准单元聚类”方法部分,我们添加了“使用 hMETIS 进行聚类后,我们根据物理综合的初始布局(芯片设计流程中的前一步)使用启发式方法重新平衡簇大小”。消除此步骤似乎对性能没有影响,如表1所示。
在 TPU 块的描述中,我们将“最多几百个”更新为“最多 107 个”和“最多 131 个”,以分别反映预训练和测试集中的宏数量。无论如何,AlphaChip 已在生产中使用了包含超过 500 个宏的块。
在相关工作中,我们添加了对参考文献的引用,作为非线性优化中加权平均的附加示例。
我们还想澄清一下,Anna Goldie 和 Azalia Mirhoseini 是原始《自然》文章的共同第一作者,她们名字的顺序是通过抛硬币决定的。
展望未来:人工智能方法将改变整个芯片设计过程
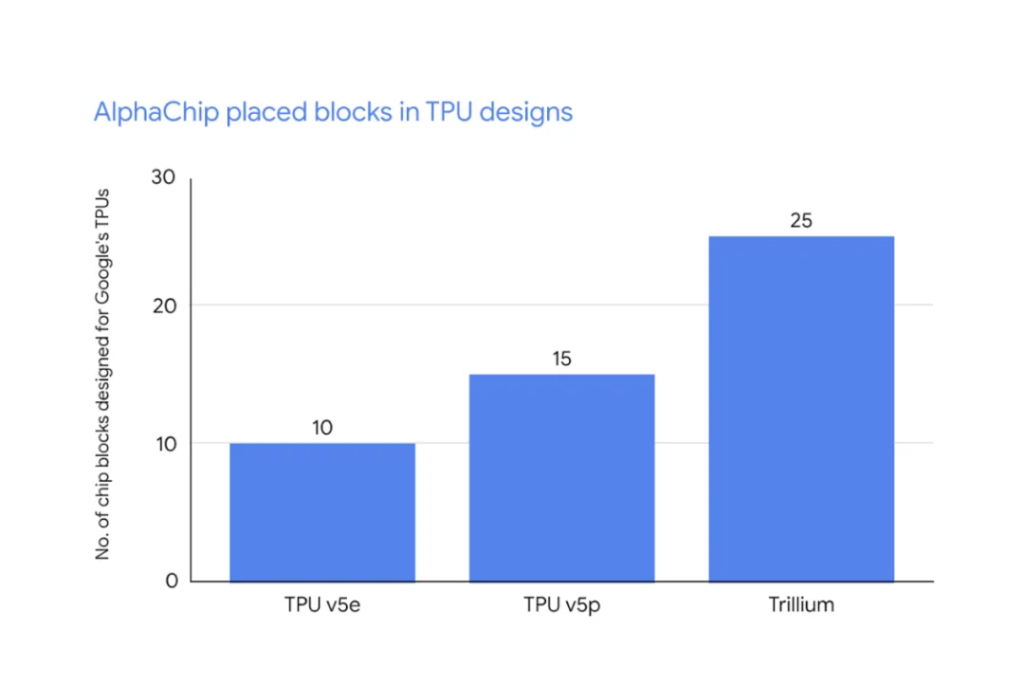
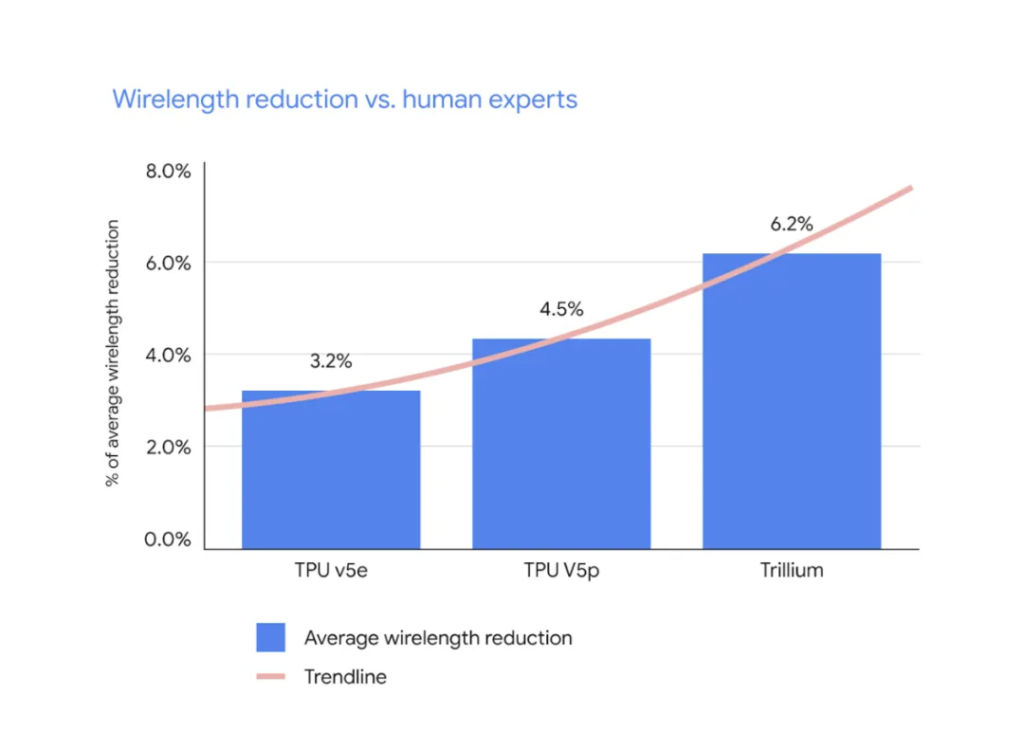
自从在《自然》杂志上发表以来,AlphaChip 已被用于谷歌旗舰 AI 加速器张量处理单元 (TPU) 的另外三代。这些芯片已在世界各地的数据中心生产和部署。随着 TPU 的每一代发展,AlphaChip 与人类专家之间的性能差距越来越大,从 TPU v5e 中与人类专家相比 10 个 RL 放置的块和线长减少 3.2%,到 TPU v5p 中 15 个块和线长减少 4.5%,再到 Trillium 30中 25 个块和线长减少 6.2% 。AlphaChip 还为数据中心 CPU(Axion)和 Alphabet 内部其他未公布的芯片中使用的块生成了超越人类的芯片布局。其他组织也采用了我们的方法并在此基础上进行构建。例如,全球领先的芯片制造商联发科扩展了 AlphaChip,以加速其最先进芯片的开发,同时提高功耗、性能和面积。
AlphaChip 只是一个开始。我们设想的未来是,人工智能方法将使整个芯片设计过程自动化,通过超人算法和硬件、软件和机器学习模型的端到端协同优化,大大加快设计周期并解锁性能的新领域。我们很高兴与社区合作,在芯片设计的人工智能和芯片设计的人工智能之间建立闭环。






