
也许并不是每个人都同意这个说法,因为今天发布的ML Perf 0.7评级的结果可能会略有不同,例如,NVIDIA在谈论市场在售的解决方案中最快的超级计算机-当然是基于A100。Google使用的是还未发布的TPU v4。
当谈到机器智能系统时,通常意味着要么使用已经训练过的神经网络,要么训练新的网络。后者需要更多数量级的计算能力,并使用功能强大的多核系统。MLPerf测试套件通常用于评估性能。至于MLPerf 0.7参与者的完整列表以及详细的结果,可以在MLPerf项目网站上找到。

Google长期以来一直在开发自己的用于机器学习的加速器:早在2017年,我们描述了首批能够快速进行256×256矩阵乘法的TPU模型。再近一段时间,第三版的TPU的在“训练”神经网络领域创造了许多新记录。打破纪录的系统的基础是Cloud TPU Pod模块,每个模块都包含1000多个Google TPU芯片并开发了100多个Pflops。
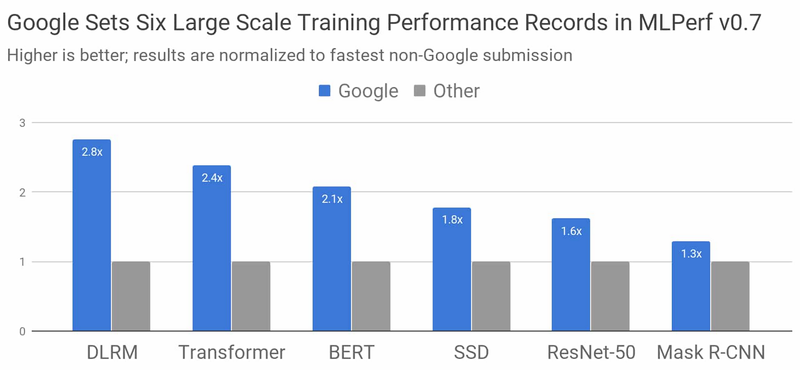
Google在这一领域的主要竞争对手就是NVIDIA了,NVIDIA也非常重视AI加速器的开发。甚至基于V100的解决方案都可以轻松地与Google TPU v3进行竞争,而最新的基于Ampere架构的A100在MLPerf Training中展示了更高的性能水平。
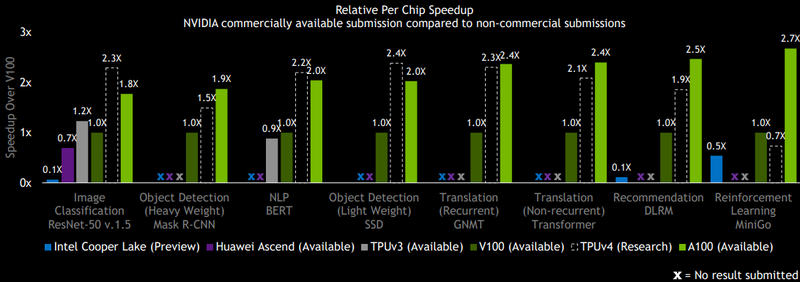
但是,谷歌不会放弃,谷歌研究部门已经发布了MLPerf Training 0.7的最新测试结果,该测试是基于尚未发布的TPU v4张量协处理器。不可能在所有测试中都打败A100,但事实证明这是相当值得的,在某些情况下,NVIDIA的速度更快,但在其他情况下,Google的开发则处于领先的地位。
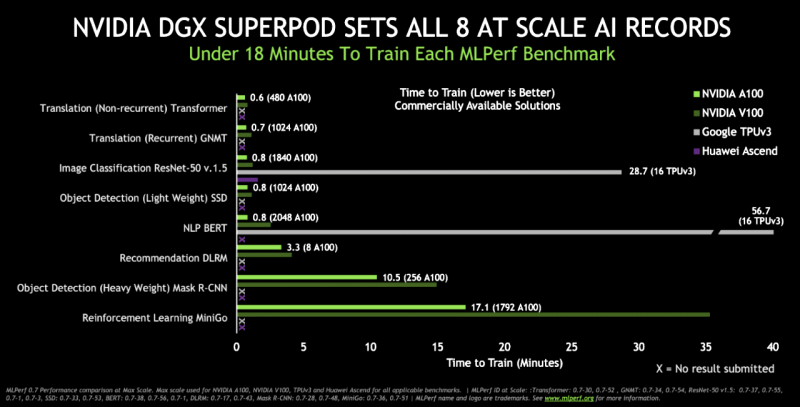
NVIDIA反过来报告了最新DGX A100的16条记录,并单独指出其产品是可以供货的(并运行任何ML Perf测试或实际负载),而竞争对手的结果通常是不完整的或无法通过硬件获得的,只是实验性质的,而无法实际获得。
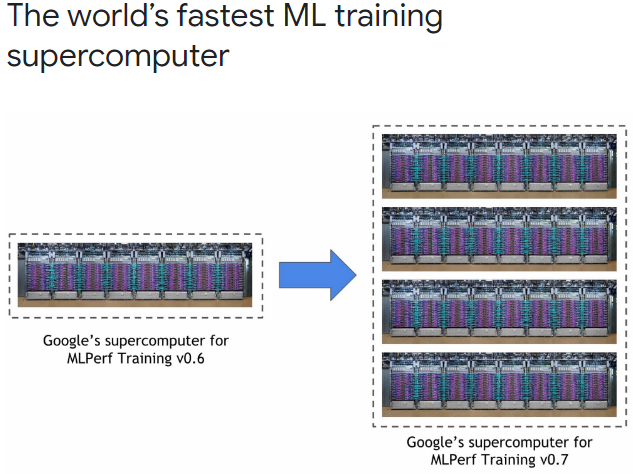
Google新的TPU测试平台包含的AI协处理器数量是上一代的四倍,数量达到了4096。
为了进行测试,我们在TensorFlow,JAX,PyTorch,XLA和Lingvo中使用了AI模型的实现。在不到30秒的时间内,“训练”了八个模型中的四个,这是非常令人振奋的结果。为了进行比较,在2015年,在当时的现代硬件上,类似的学习过程花费了三个多星期。总的来说,TPU v4有望比TPU v3快2.7倍,但Google协处理器第4次迭代的正式发布将使其成为现实。
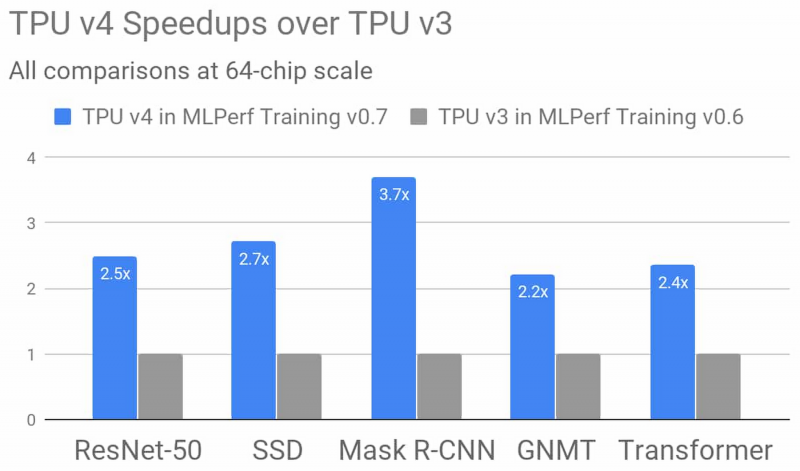
有关测试MLPerf 0.7的更多信息,请查看官方的Google Cloud博客。你还可以在此处找到有关基于TPU系统的详细信息,但是此信息仍然仅限于该芯片的第三版。迄今为止,已知第四代TPU在矩阵乘法运算中的速度是第三代的两倍以上,拥有更快的存储子系统并具有改进的互连系统。





