
我们未必完全认同本文标题的论断,现在下结论或许为时尚早,毕竟CXL不仅涉及带宽提升,还承载着统一异构编程的潜力。本文的意义在于揭示不同SerDes类型在带宽上的差异,如何导致技术路径在延迟与性能上的分野。
01 人工智能加速器的“边缘之争”、内存池的局限与定制芯片的兴起
若将时间拨回两年前,也就是人工智能热潮尚未席卷之时,数据中心硬件领域几乎都在追捧CXL。这项技术被视为实现异构计算、内存池化和可组合服务器架构的“灵丹妙药”。当时,许多老牌企业和初创公司争相将CXL融入产品,或研发基于CXL的创新设备,如内存扩展模块、内存池硬件和交换机。然而,到了2023年及2024年初,不少项目已悄然搁浅,大型云服务商和半导体巨头纷纷转向其他方向。
随着Astera Labs即将IPO和发布新品,CXL的话题短期内重回公众视野。我们曾多次探讨这一技术,从其为云服务商节约成本的潜力,到生态系统与硬件堆栈的构建。尽管CXL在理论上前景诱人,但数据中心格局已今非昔比。唯一不变的是,CXL硬件(如控制器和交换机)的出货量仍未达到显著规模。尽管如此,业内仍有不少关于CXL的讨论,有人甚至开始宣称它是人工智能的“加速器”。
CXL市场是否已蓄势待发,能否兑现其承诺?它能在人工智能互连中占据一席之地吗?在CPU扩展和内存池中又扮演何种角色?这些问题将在订阅报告中详解。简而言之,我们认为答案是否定的——将CXL推向人工智能的观点站不住脚。以下是对CXL主要场景的简要回顾。
02 CXL核心场景速览
CXL是基于PCIe物理层的协议,支持设备间的缓存和内存一致性。借助普及的PCIe接口,CXL能在CPU、NIC、DPU、GPU、加速器、SSD及内存设备间共享内存,开启以下应用可能:
- 内存扩展:提升服务器内存带宽与容量。
- 内存池化:将内存从CPU分离,形成共享池,理论上可大幅提高DRAM利用率,为云服务商节省巨额成本。
- 异构计算:通过低延迟的缓存一致性互连,CXL助力ASIC与通用CPU协同工作,推动高效异构计算。
- 可组合架构:将服务器拆分为组件并动态分配资源,优化利用率并适配工作负载需求。
如下图所示,CXL填补了主内存与存储间的延迟与带宽鸿沟,构建新的内存层级(图表源自SNIA)。
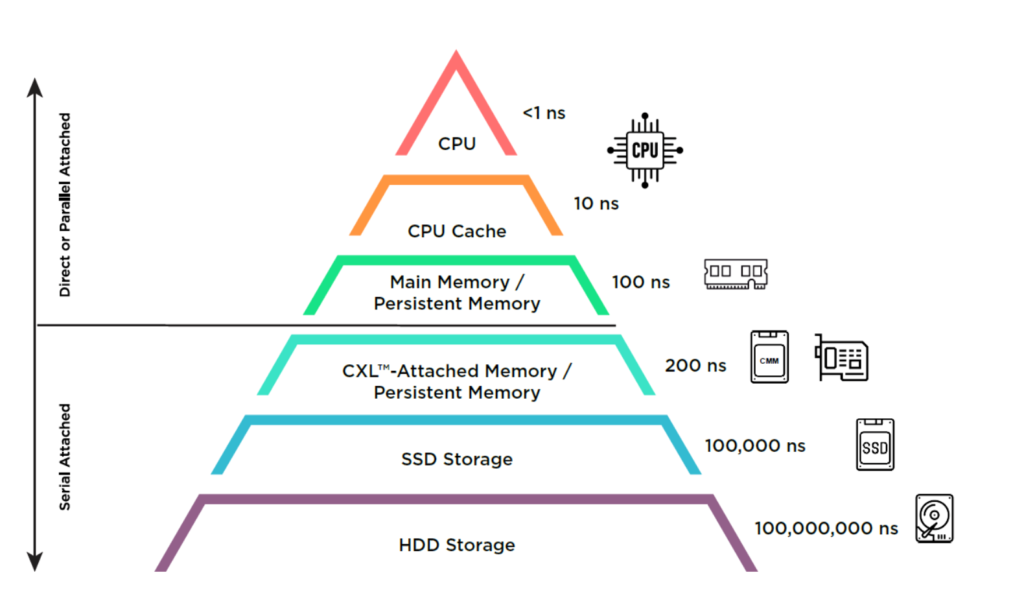
有人预测,到2028年CXL市场规模将达150亿美元,而当前仅数百万美元。这一乐观预期令人质疑,我们认为有必要重新审视CXL市场,尤其是其在人工智能中的角色。
03 CXL难成人工智能互连主流
当前,CXL面临的最大瓶颈是可用性。英伟达GPU不支持CXL,AMD的MI300A虽兼容,但MI300X未充分开放相关功能。未来CXL IP的可用性或将改善,但更深层次的问题使其在AI加速时代难担重任。
问题核心在于PCIe SerDes和“芯片边缘”面积。芯片I/O通常集中于边缘。以英伟达H100为例,核心区域负责计算,上下边缘完全用于高带宽内存(HBM)。从H100到B100,HBM增至8个,占用了更多边缘空间(见Locuza示意图)。

剩余两侧则用于其他I/O,如PCIe、NVLink和C2C(连接Grace CPU)。英伟达优先选择NVLink和C2C,仅保留16个PCIe通道,而AMD Genoa CPU可支持128个。
带宽是关键驱动因素。16通道PCIe 5.0双向带宽仅64GB/s,而NVLink为其他GPU提供450GB/s,C2C为Grace CPU带来同等带宽,差距约7倍。即使考虑芯片面积分配,以太网风格SerDes(如NVLink、谷歌ICI)的每平方毫米带宽仍超PCIe约3倍。若选择PCIe 5.0而非112G SerDes,性能将缩水三分之一;在下一代224G SerDes与PCIe 6.0/CXL 3.0的对比中,这一差距依然存在。在引脚受限的现实中,牺牲I/O效率并非明智之举。
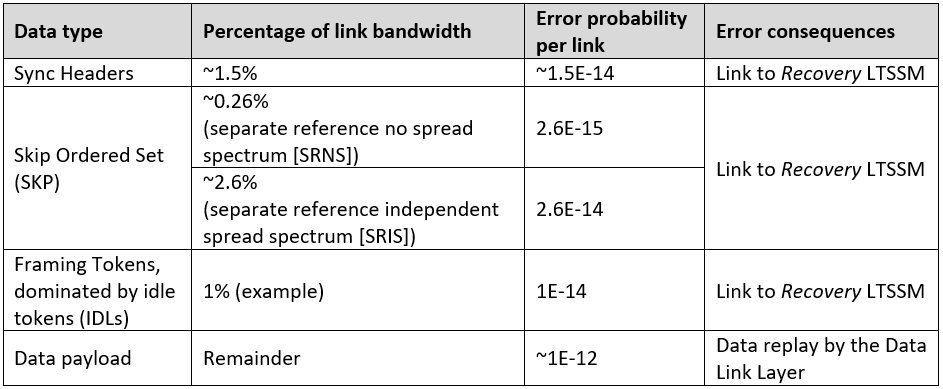
因此,人工智能集群的互连将更倾向于NVLink、谷歌ICI、以太网或Infiniband,而非PCIe基CXL。延迟目标的不同进一步加剧了这一分化。PCIe 6要求误码率低于1e-12,需轻量级FEC以确保低延迟;而以太网仅需1e-4,可采用复杂FEC提升带宽(见Astera Labs示意图)。NVLink延迟略高,但对AI并行负载而言,100纳秒与30纳秒的差异微不足道。
AMD MI300 AID虽在PCIe SerDes上投入较多边缘面积,提供CXL灵活性,但I/O总量仅为以太网风格SerDes的三分之一。若想挑战英伟达B100,AMD需在MI400中转向专用互连。
结语
CXL曾被寄予厚望,但其在人工智能时代的适用性正受质疑。带宽瓶颈与芯片设计权衡限制了其潜力,而专用互连更契合AI需求。至于CXL在内存扩展与池化中的价值,以及云服务商定制芯片的趋势,我们将在后续探讨。尽管CXL仍有研究空间,但其难以成为AI互连的主流技术。