


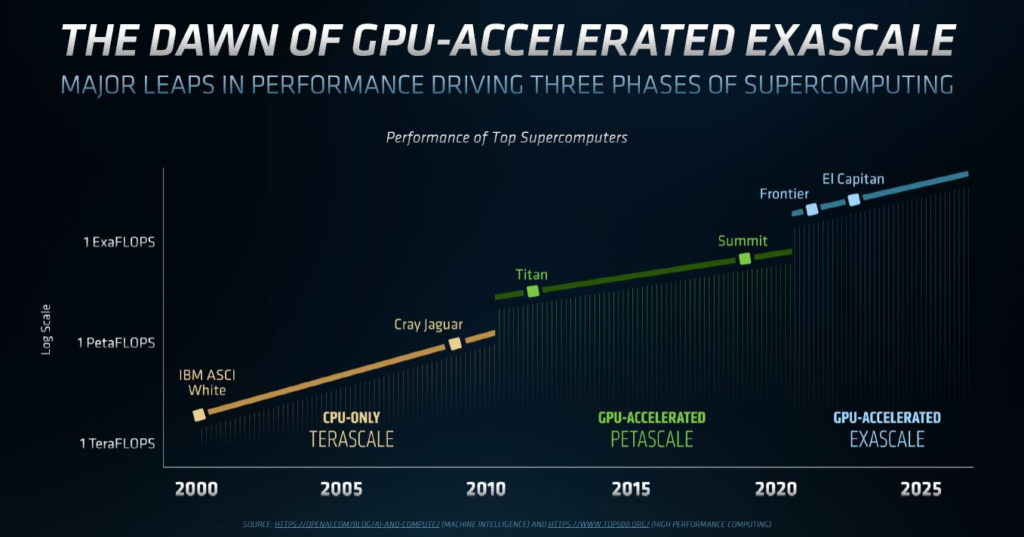
前几天,NVIDIA A100 GPU已从40GB升级至80GB,今天,我们已经得到了其主要(当前)竞争对手AMD对NVIDIA A100 GPU的回应:Instinct MI100 32GB CDNA GPU。AMD一直在吹捧一种新的体系结构,专门用于以低成本提供许多HPC触发器。让我们看一看AMD的这款新的CDNA产品。
AMD INSTINCT MI100背景
让我们简要地介绍一下背景,AMD Instinct MI100是采用一种不一样设计的体系结构。AMD意识到,传统GPU就其”图形”处理而言,通过加入逻辑单元来帮助快速渲染游戏是非常低效的,所以,正如我们在最近的AMD Radeon RX 6900 XT 6800 XT和6800 Launch中介绍的那样,AMD将其GPU的工作分开针对游戏领域的RDNA和对于数据中心领域的CDNA。


在所有这些背景介绍的幻灯片中,我们并没有那么微妙的针对NVidia。例如,在上面,我们用的”通用”实际上是NVIDIA的Ampere设计。下面,AMD指出它已经获得了公共能源部百亿亿美元认证。英特尔也是如此(尽管也许HPE-Cray在这里是最大的赢家),而NVIDIA在第一轮亿亿级合同中却没有赢。

“NVIDIA的芯片为超级计算机提供的不仅仅是高性能计算,并不专注在通过诸如支持稀疏性等功能来对AI加速。所以,原始FP64的性能提升不足以满足百亿亿级的需求”,AMD如此介绍到。

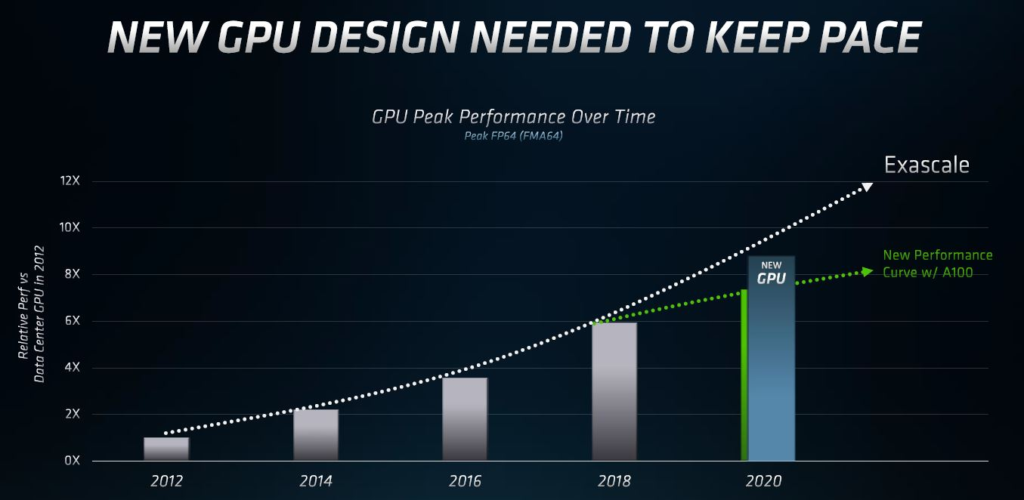
英特尔方面也作了相同的表述,但是AMD如今在其领域推出了新产品,而Intel则发布了视频转码服务器GPU。
AMD INSTINCT MI100总览
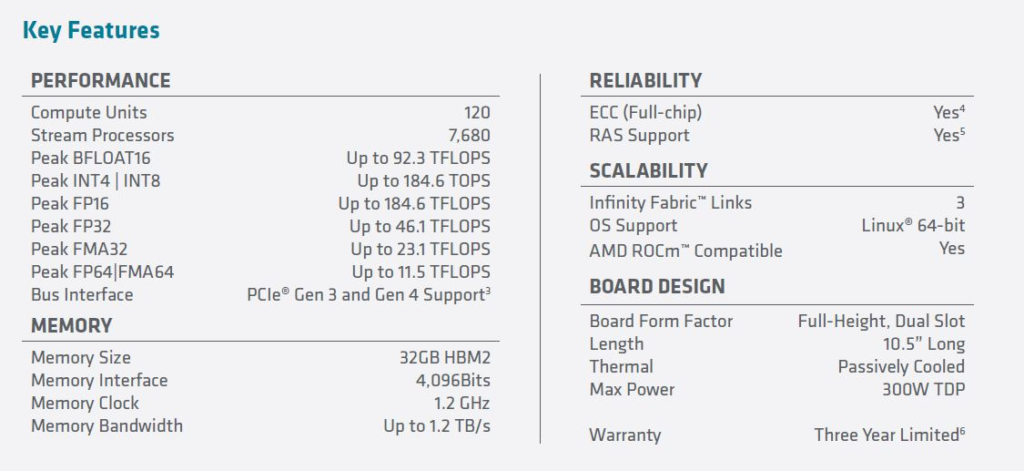
AMD Instinct MI100 GPU是AMD针对GPU在HPC计算领域的新产品。 我们将在稍后讨论与A100相比的“峰值性能/价格”,让我们首先了解以下主要规格。


这是一个32GB HBM2内存的GPU,比上一代产品具有更高的内存带宽和更高的计算密度。


以下是Marketing幻灯片中写的规格:


我们可以看到,我们有一个可以插入标准PCIe Gen4 x16插槽的具有11.5 TFLOP(峰值)的GPU,这儿我们想提的一点是Infinity Fabric Link,如本文封面所示,Instinct MI100是被设计成可以在四个GPU”配置单元”中同时运行。AMD使用Infinity Fabric来给GPU到GPU的通信提供比PCIe Gen4更高的性能,有点像NVIDIA的NVLink。考虑到与MI100同时发布的A100 80GB之前,NVIDIA已经达到了40GB容量,我们特意询问了AMD 32GB HBM2容量是不是足够,AMD表示,这是控制HPC客户成本的最佳选择,就像HPC客户通常更关心填充内存通道而不是能够达到CPU的高存储容量。

这是从公司提供的框图快速绘制出新的Instinct MI100的示意图:

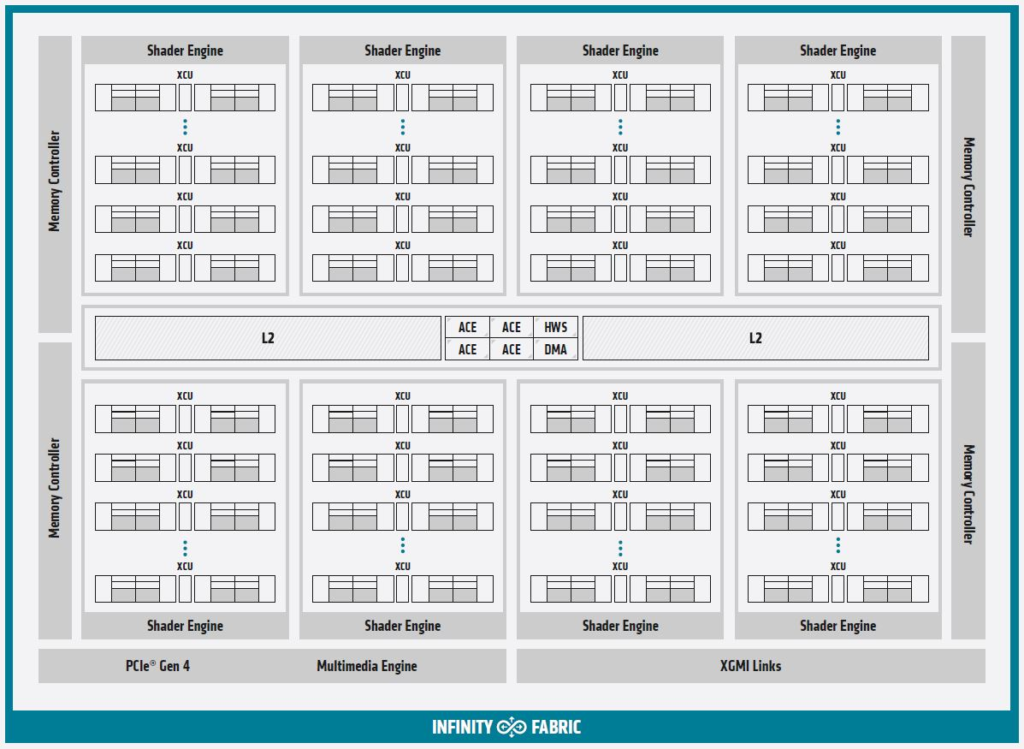
许多加速来自新的pipeline。下面是“增强计算单元”的外观。我们有些读者会跳过这一点,而另一些读者则希望看到详细信息。AMD拥有一份包含更多详细信息的新白皮书,但是,如果你想了解更多有关AMD在底层是如何处理的,请随时阅读图表。

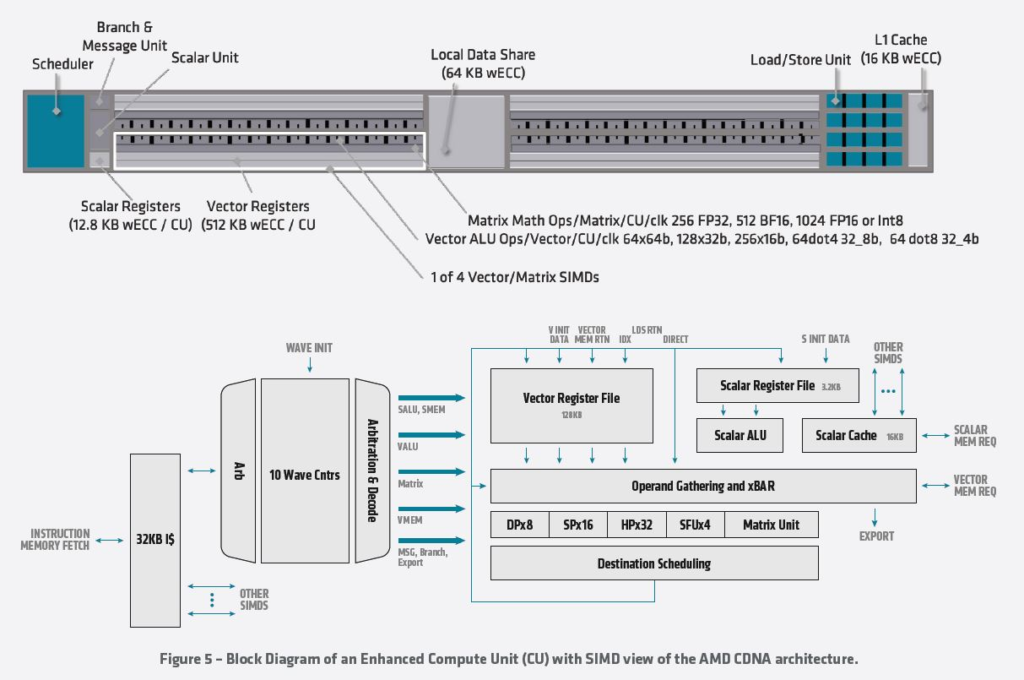
最终的影响是AMD Instinct MI100是单个300W PCIe卡,峰值为11.5 TFLOP。AMD对新的300W PCIe GPU和使用6MW并占用许多机架的2000年#1超级计算机进行了强制性比较。 在计算方面,2000年是很久以前,而当时的Intel Pentium还是高级品牌。


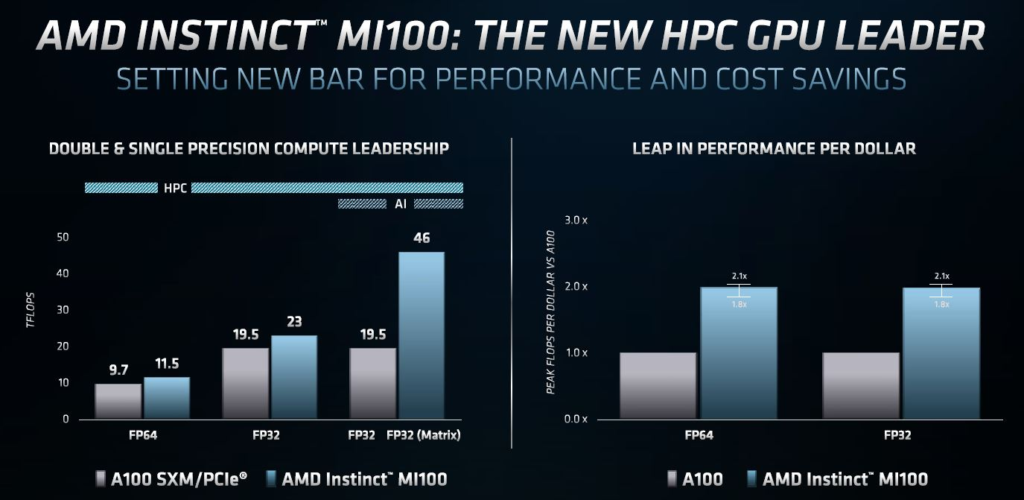
AMD讨论的部分内容是每美元的计算能力和每美元的性能,新款7纳米GPU的板载内存更少,可支持32GB HBM2,而NVIDIA的A100为40GB或80GB。同时我们也要看到,借助新的NVIDIA A100 80GB,NVIDIA可以降低40GB型号的价格,所以对下表还是有一些影响的。
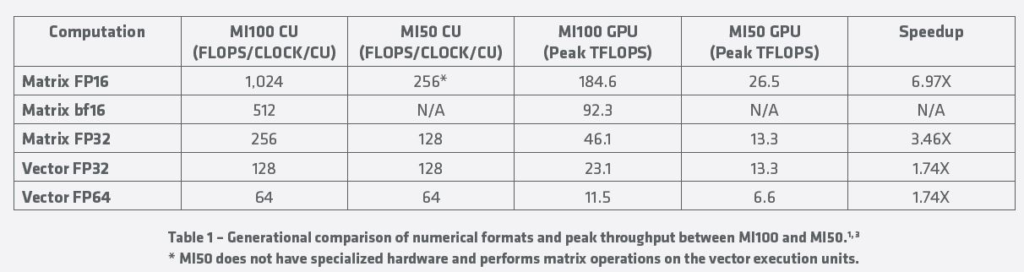
AMD不仅与NVIDIA进行了比较,还将其新芯片与当前的Instinct MI50进行了比较。下表显示了一些巨大的性能提升,在流行的FP16格式中,性能提升接近7倍。

既然我们知道AMD已经赢得了几笔百百亿计算机合同,例如El Capitan 2 Exaflop超级计算机,我们看到橡树岭国家实验室(ORNL)作为早期采用者讨论了性能提高。我们也注意到,AMD在这里也与MI60进行了比较,而不是上面的MI50。AMD还在将其与NVIDIA V100(而不是当前的A100)进行了比较。


我们所知道的是,这些超级计算机的购买者是非常聪明的人。显然,AMD向这些人展示了MI100及其后续产品是足够好的,以至于NVIDIA没有赢得这些合同。当然,AMD希望将其下一代显卡用于亿万亿次存储计划,但需要在其GPU上运行行业软件。为此,AMD的ROCm也已更新。
AMD ROCM 4.0 更新
部分消息是AMD ROCm 4.0已经发布,随着每一代ROCm的出现,该公司将覆盖更多的用例和场景。该公司有一项艰巨的任务,那就是其GPU计算和NVIDIA GPU一样可以运行CUDA。ROCm允许AMD及其客户轻松移植CUDA应用程序和其他组件以可以在AMD GPU上运行。


明年,有了ROCm 5.0,我们可能会看到更多些有关ROCm 4.0如何不完整而ROCm 5.0具有完整的覆盖率的信息,至少这是我们从过去几代产品的经验中可以预见的。ROCm 4.0带来了更大的性能提升,从而为现有GPU计算用户减轻了移植的痛苦。


这是这些亿万美元的能源部合同发挥作用的地方。部分合同不仅限于硬件本身,还涉及围绕下一代系统来开发工具。AMD正在对ROCm加大投入,以确保该软件在其旗舰系统开始上市时就可以运行。Intel一直在谈论OneAPI的好处,但是AMD很有可能会为第一个亿亿级系统提供动力。
AMD INSTINCT MI100的合作伙伴
如前所述,AMD的数据中心基本按照4个GPU与1个CPU的比率配置。在这里,AMD显示每个”配置单元”有四个AMD Instinct MI100 GPU,每个AMD EPYC 7003 “Milan” CPU则配置一个”配置单元”。


如果你同时查看封面图像和上面的图像,则可以看到卡的底部具有PCIe Gen4连接器,但卡的顶部具有特殊的桥接器,可以进行GPU与CPU间的通信。NVIDIA具有NVLink和自定义SXM4尺寸的NVIDIA A100 4x GPU HGX Redstone平台。


支持这些设计的是HPE,Dell,Supermicro和Gigabyte的系统。你可能在我们的戴尔和AMD展示的“服务器的未来” 160 PCIe通道设计一文中看到过Dell EMC PowerEdge R7525。我们也希望这些平台也支持AMD EPYC 7003“Milan”一代。







