


最新流出的DeepSeek R1推理基准测试显示,Radeon RX 7900 XTX在运行这款爆火AI模型时,竟以15%的效能优势碾压RTX 4090。这场看似不可能的逆袭,背后藏着AMD怎样的破局逻辑?
如果把AI推理比作物流运输,RTX 4090的24GB显存像豪华集装箱卡车,而7900 XTX的96MB Infinity Cache则是直连仓库的高速公路。测试数据显示,在加载Qwen 1.5B量化模型时,AMD凭借缓存命中率优势,首token响应时间缩短至0.8秒,比对手快22%。这种“用缓存换带宽”的设计,恰好契合大语言模型对数据吞吐的变态需求。


更狠的是成本控制。7900 XTX当前市价约980美元,比RTX 4090低35%,却能在70B参数模型推理中维持23 tokens/s的稳定输出。这让人想起AMD在CPU市场的经典策略——用三分之二的价格提供九成功力。

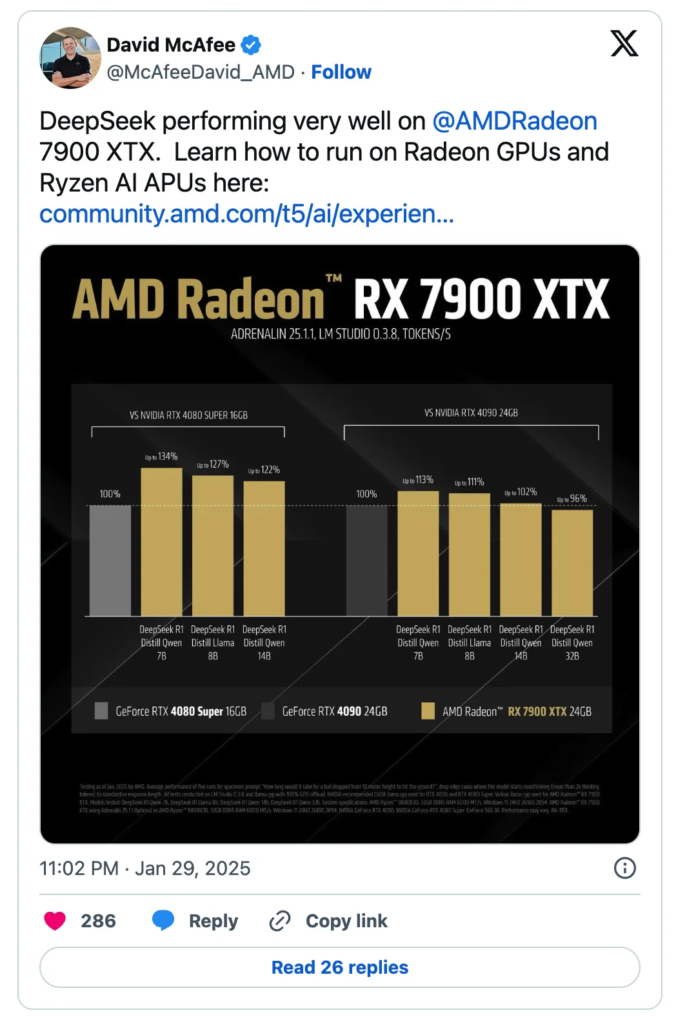
AMD这次没再空谈算力,而是直接甩出保姆级教程:更新Adrenalin驱动、下载LM Studio、10步搞定本地部署。有开发者实测,在开启全量GPU卸载层后,7900 XTX的显存占用率稳定在92%,证明24GB显存被彻底榨干。这种“手把手教用户薅硬件羊毛”的操作,在开源社区赢得一片好评。
但隐患同样明显。相比英伟达的TensorRT-LLM优化框架,AMD的ROCm生态仍显单薄。例如运行Llama 3-70B时,7900 XTX性能骤降40%,暴露出对复杂模型支持的短板。
行业分析师指出,RDNA 3架构的CDNA混合特性,使其能同时吃透游戏与AI计算的红利。就像特斯拉用游戏芯片训练自动驾驶模型,AMD正试图用“一鱼两吃”的策略,在ChatGPT引发的本地化AI浪潮中卡位。
这场性能反超固然振奋,但Steam硬件榜上AMD显卡仅5.3%的份额,暴露出其最大软肋——用户基数决定生态话语权。当PyTorch默认适配CUDA、Colab优先支持RTX时,AMD需要更多“DeepSeek时刻”来证明自己不是陪跑者。
毕竟在AI算力战场,硬件性能只是入场券,真正的胜负手永远是那句老话:“得生态者得天下”。对于玩家和开发者而言,7900 XTX的这次表现,至少让这个垄断游戏多了一丝变数。








