摘要
随着我们向超融合的云解决方案迈进,分布式文件系统在云租户端(即客户端)的效率和开销变得至关重要。通常,云文件系统的客户端驱动程序复杂且占用CPU资源,与后端实现紧密耦合,并需要优化多个干扰性较大的参数。
在本文中,我们提出通过使用Linux virtio-fs软件堆栈,将文件系统客户端从其后端实现解耦,并使用现成的DPU进行虚拟化。通过解耦,我们能够将文件系统客户端的执行任务卸载到由云服务商管理和优化的DPU上,同时释放主机的CPU资源。我们提出的框架(DPFS)每个I/O的主机CPU效率提高了4.4倍,可以在无需配置和不修改其主机软件堆栈的情况下,提供与租户相当的性能,同时允许工作负载和硬件特定的后端优化。DPFS框架及其相关资料已公开在(https://github.com/IBM/DPFS)上提供。
引言
在云数据存储领域,文件系统是备受青睐的选择,包括传统的分布式文件系统(如HadoopFS、Ceph、GlusterFS),以及云原生文件系统(CNFS,Cloud-Native File Systems)服务,如Amazon EFS [3]、Alibaba Pangu [10]或Azure Files [27]。随着对超融合基础设施的推动[13],对于高效、可扩展和高性能的云原生文件系统服务的需求日益迫切。
为应用程序构建高性能、可扩展的云原生文件系统是一项具有挑战性的任务。
- 首先,存储和网络设备的原始性能不断提升,而CPU性能的增长已经停滞不前[29, 44]。因此,在分离式存储环境中实现I/O设备的全速运行需要大量的CPU资源[17, 43]。例如,Alibaba报告称需要使用12个CPU核心来实现200Gbps的块级流量传输[26]。在文件系统层面,LineFS报告称,在100 Gbps的链路上,通过Ceph,一个完全利用的CPU只能达到约10Gbps的带宽[16]。CPU效率问题对于裸金属机器也很重要,这在云中近年来变得流行 [6, 34, 48]。
- 其次,客户端CNFS逻辑可能会很复杂和臃肿,因为它必须实现与元数据和数据服务器的通信和协调逻辑,客户端缓冲区和连接管理,缓存等。因此,分布式文件系统客户端通常会消耗大量的DRAM并且消耗大量的CPU计算资源,从而限制了服务器上可以同时运行的租户(虚拟机、容器)的数量[2, 21]。
- 最后,文件系统API与其实现的紧密耦合使得部署新扩展或优化变得困难。例如,使用Ceph的裸金属租户如果遇到元数据可扩展性挑战,就无法轻松切换到HopsFS [30] 或 InfiniFS [25]。此外,许多这些CNFS都带有数百个性能调节参数和功能,需要租户方面的显式部署和优化才能提取出最佳性能。
为了解决上述挑战,我们提出通过将文件系统客户端卸载到DPU以实现虚拟化,从而提供租户透明、轻量级、高性能的文件系统服务。这种设计具有多个优势:
- 首先,虚拟化将文件系统API与其后端实现分离,这使我们能够优化后端以支持多个工作负载需求,如多个API[22]、可扩展的元数据查找与KV存储、数据与元数据管理的解耦[19]。云服务商目前以NFS网关的形式提供了一种有限的解耦,以支持CNFS客户端[3, 12, 27]。我们认为这种方法会将文件系统客户端的控制权交给云服务商,并且展示了Linux内核NFS客户端存在较高的开销(§3.4)。
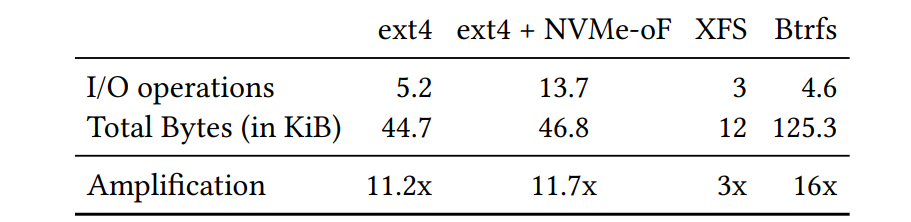
- 其次,通过将文件系统实现卸载(并利用DPU的硬件加速),我们为租户释放了主机CPU资源。可以主张,主机也可以在块级或应用程序级别利用卸载能力。块级卸载允许完全可卸载的I/O栈[20, 28],但会导致显著的I/O扩增。我们在表1中量化了这种扩增[24],其中我们报告了对单个4 KiB文件写入操作产生的块级或网络级操作(用于NVMe-oF存储分离的数据包)。根据文件系统,扩增可以高达3-16倍,因此需要硬件卸载的相应增益。此外,与本地块I/O相比,NVMe-oF还会扩大所需的平均I/O操作数量(5.2 vs. 13.7)。
- 另一方面,通过文件系统级虚拟化,这将是一个从主机到DPU的单个可卸载文件操作,然后从DPU到文件系统后端。应用程序级的解决方案需要重新编写应用程序以从DPU的卸载能力中受益,这是非常复杂且非标准化的(除了RDMA和NVMe-oF风格的卸载)。
- 最后,基于DPU的设计不需要租户进行任何微调或配置。所有与CNFS相关的配置和优化都可以在DPU上集成,在云服务商的监督下,为租户释放主机CPU。DPU(运行云服务商逻辑)与主机上的租户(在主机上)之间的物理隔离还可以防止基于资源共享的侧信道攻击[6],从而提高租户隔离和安全性。
在本文中,我们提出了DPFS,这是一个用于云环境的基于DPU的文件系统虚拟化框架。DPFS利用virtio-fs协议在主机和DPU之间进行通信。DPU和主机通过PCIe内存映射的virtio [38] 队列使用FUSE文件I/O命令集进行通信。由于virtio-fs已经在Linux内核中标准化 [46] 并且已包含在Linux内核中 [37](无需安装),这个设计使DPFS能够避免在主机上运行定制的CNFS客户端的需要。通过在DPU上采用前端(标准文件系统API)与其后端实现(即CNFS)之间的解耦设计,使用DPU上的“中间件架构”(bump-in-the-wire) [9],云服务商可以进行各种网络和存储优化(调度、缓存、配额、QoS),而无需租户执行任何代码安装或更改任何配置。为了证明DPFS的灵活性,我们已经实现了三个文件系统后端:(i)DPFS-null,一个用于开发和基准测试的无操作DPU客户端;(ii)DPFS-NFS,一个在DPU上运行的NFS后端,将virtio-fs请求转换为等效的NFS命令,并使用libnfs与Nvidia XLIO(部分TCP offloading) [33] 与远程NFS服务器进行通信;(iii)DPFS-KV,一个基于RAMCloud的后端,用于在小文件上实现低延迟的I/O操作,适用于KV存储 [35]。
在本工作中,我们的主要贡献包括:
- 我们为使用DPU进行云原生文件系统的透明文件系统访问虚拟化提出了论据。
- 我们提出了DPFS的设计和实现,这是一个支持Nvidia BlueField-2 DPU [32] 的开源文件系统虚拟化框架(https://github.com/IBM/ DPFS)。
- 评估DPFS,证明它(i)轻量级;(ii)提供与主机NFS客户端相同甚至更好的性能;以及(iii)具有多个文件系统后端实现的可定制和模块化能力。
DPFS 设计与实现
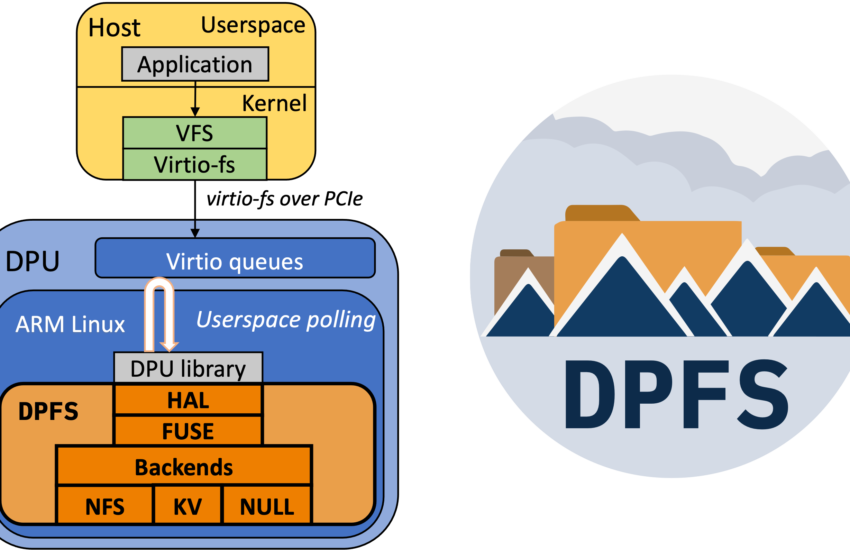
为了加速基于DPU的文件系统的开发,我们实现了DPFS框架。该框架由三个层次组成,每个层次都有不同的目的,如图1中的橙色部分所示。
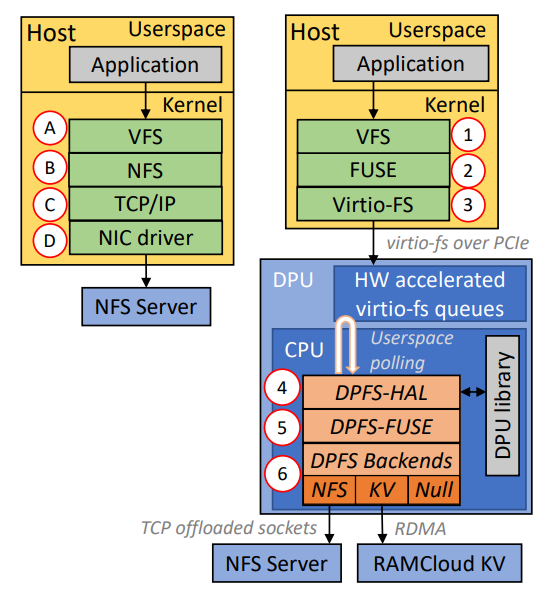
绿色方框代表标准内核代码,橙色方框代表我们的贡献
第一层(DPFS-HAL)为供应商特定的DPU功能和主机-DPU优化提供了硬件抽象层(HAL)。其作用是减少开发文件系统后端所需的DPU特定知识,简化代码维护,并允许更快地过渡到新类型或新模型的DPU。第二层在原始virtio-fs协议缓冲区之上实现了类似FUSE的API(即libfuse [1])(DPFS-FUSE §2.2)。第三层包含文件系统后端实现(即允许连接到远程文件系统的DPU逻辑)。
在这里,我们提供了三个实现。第一个客户端是DPFS-null,它实现了一个立即回复任何请求的空操作后端。该后端用于优化和基准测试主机-DPU通信,即DPFS-HAL和DPFS-FUSE层。第二个客户端是DPFS-NFS(§2.3),这是一个优化的用户空间NFS客户端,允许连接到现有的基于云的NFS文件系统服务。使用这个客户端,云服务商无需对现有的文件系统后端进行任何更改,即可使用DPU虚拟化。第三个客户端是一个键值客户端(DPFS-KV §2.4),它连接到一个基于RAM-Cloud [35] 的后端,并利用RDMA来访问存储在KV存储中的文件。过去的研究已经证明,KV存储可以更好地适用于文件系统实现 [18]。
2.1 DPFS I/O 路径
在主机NFS客户端配置中(见图1,左侧),应用程序提交与文件相关的系统调用(例如read()调用),然后上下文切换到内核。请求经过VFS A和NFS B层,然后经过TCP/IP堆栈C,最后发送到网卡驱动程序D。网卡与文件系统后端进行通信。在接收到响应后,通过中断启动反向路径。
另一方面,DPFS I/O路径(见图1,右侧)在主机上要轻量得多,无需应用程序或内核修改。请求首先通过VFS层1,然后转发到轻量级FUSE层2,将VFS操作转换为FUSE请求消息。然后将FUSE请求传递给virtio-fs层3,它将消息封装并通过PCIe传输,通过虚拟函数传递给DPU上的适当主机租户和virtio队列。在DPU上,DPFS-HAL线程从队列中检索消息4,然后将其传递给DPFS-FUSE 5。DPFS-FUSE提取原始FUSE请求并将其转发到文件系统后端6。
代码路径的复杂性可以通过Linux内核(v6.2)中的代码行数大致估算。步骤B-C包含181k行源代码(假设为IPv4),而步骤2-3包含13k行源代码。在DPU上,客户端在用户空间操作,因此不需要上下文切换。此外,DPU上的文件系统后端可以使用RDMA和TCP offload等硬件加速。总体而言,主机上的代码路径和每次操作的CPU开销都大大减少,正如我们在§3.4中所示。
我们强调,virtio-fs以一种使其传统上较大的开销不会发生的方式使用了FUSE。virtio-fs协议使用FUSE对Linux虚拟文件系统(VFS)操作进行标准化编码成FUSE-ABI。传统的FUSE编码VFS操作并将其发送回用户空间以由用户空间文件系统实现处理,导致两次额外的上下文切换和显著的开销 [47]。相反,virtio-fs使用FUSE对VFS操作进行编码,并将它们直接从内核空间发送到virtio-fs PCIe设备(即DPU),因此不会产生额外的上下文切换。
2.2 DPFS-HAL 和 DPFS-FUSE 实现
在基于DPU的virtio-fs功能之上实现文件系统的两个主要挑战之一是透明地处理DPU的软件堆栈。这包括配置软件堆栈、virtio-fs队列,实现高效的轮询和调度。对于我们的DPU(Nvidia BlueField-2),固件通过InfiniBand verbs将virtio-fs设备在用户空间中暴露为RDMA设备。Nvidia提供了一个库(Nvidia SNAP)来设置和配置virtio设备,并暴露virtio-fs功能。然而,DPFS-HAL(硬件抽象层)通过仅暴露DPU软件堆栈的virtio-fs相关配置参数,隐藏了这些复杂性。DPFS-HAL的C-API允许virtio-fs实现注册handle_request回调,在由DPFS-HAL或手动管理的线程中轮询virtio队列,并以异步方式完成virtio-fs请求。
使用DPFS-HAL暴露的virtio-fs协议来开发文件系统后端是很麻烦的,因为文件系统开发人员必须使用Linux内核通过virtio-fs协议公开的原始FUSE-ABI。由于FUSE-ABI旨在通过流行的libfuse库 [1] 来消耗,该库充当ABI的参考实现和API,因此其文档有限。DPFS-FUSE暴露了一个类似于libfuse API的C-API。通过暴露一个众所周知且常用的API,我们报告了增加的virtio-fs文件系统开发速度。文件系统开发人员可以在开发的第一步中使用用户空间FUSE,当DPU环境可用时再过渡到DPU环境。我们的DPFS-FUSE API是在libfuse的基础上构建的,增加了对异步操作的支持,并优化了函数调用,以减少数据拷贝和分配的次数。
2.3 DPFS-NFS:硬件加速的NFS后端
DPFS-NFS后端实现利用了Nvidia XLIO [33] 的加速套接字API和libnfs库 [39]。Nvidia XLIO是一个共享库,它重载了套接字C-API,以利用BlueField-2硬件中的网络卸载能力,并减少数据拷贝(并非完全零拷贝)。此实现展示了通过DPU利用硬件加速而无需对主机文件系统客户端和远程文件系统提供者进行任何更改的可能性。我们的实验显示了实现用户空间硬件加速的NFS客户端的性能优势。标准的Linux内核NFS客户端(在DPU上运行),当使用io_uring时,4 KiB访问的读取和写入延迟分别为100.5微秒和101.9微秒。仅使用软件的libnfs分别为76.0微秒和74.2微秒。将Nvidia XLIO添加到libnfs中可以进一步将延迟降低到52.9微秒和52.2微秒。
在DPFS-HAL队列轮询线程上,DPFS-NFS文件系统实现将FUSE请求转换为NFS v4.1 [31],并使用libnfs和Nvidia XLIO将NFS请求发送到远程存储后端。第二个线程使用libnfs在Nvidia XLIO套接字上轮询,将NFS v4.1响应转换回FUSE,并向DPFS-HAL轮询线程发送消息,以完成virtio-fs请求。
2.4 DPFS-KV:RAMCloud KV 存储后端
DPFS的文件系统透明性使得不需要对主机进行任何更改就可以使用专门的文件系统。我们通过为RAMCloud实现DPFS后端来演示这一点,RAMCloud是一个分布式的内存KV存储,通过利用RDMA [35] 提供低延迟的访问。DPFS-KV通过在文件系统的根目录中通过一组键值对公开了文件系统操作,其中每个文件表示一个键值对。在RAMCloud中存储两个表,第一个表用于存储数据(文件内容),第二个表用于存储元数据(属性、名称等)。为了在元数据表中进行索引(即进行readdir()操作),文件名被散列并用作键。在元数据表中存储了唯一的i节点标识符,它充当数据表的文件键。为了支持列出平面文件系统目录的内容,即readdir(),文件名本身存储在元数据表中。
评估
在本节中,我们通过DPFS-null、DPFS-NFS和DPFS-KV后端来评估DPFS的性能和效率。表2显示了我们的实验配置。所有工作负载都是使用具有io_uring I/O引擎的fio生成的。为了在系统上生成一致的负载,我们使用了两个fio线程。

3.1 虚拟化开销
我们首先测量DPFS-null后端在随机读写工作负载下的吞吐量(预热10秒,随后运行60秒)。这个实验的结果展示了DPFS可以提供的性能上限。
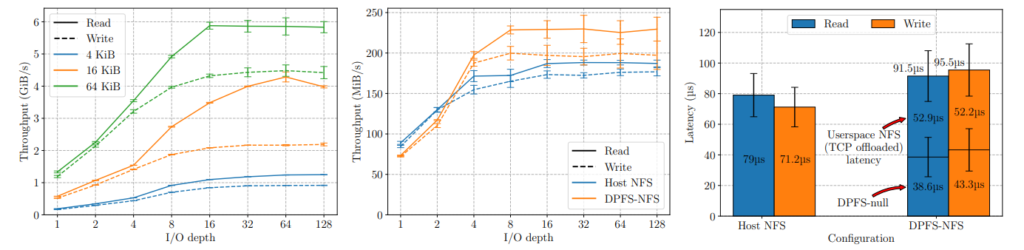
图2a显示了null-DPU后端的吞吐量(y轴,以GiB/s为单位)与I/O(队列)深度的关系。我们报告了4 KiB、16 KiB和64 KiB块大小的读写操作的吞吐量。随着I/O深度的增加,读写操作的吞吐量都会增加。使用64 KiB块大小时,当队列深度在16-32之间时,吞吐量为5.87 GiB/s(读取)和4.32 GiB/s(写入)。对于4 KiB块大小,在内核中常见的I/O大小,峰值读取吞吐量为1,278 MiB/s,写入吞吐量为938 MiB/s,分别相当于327K和240K随机4 KiB IOPS。在I/O深度为1时,我们测得读取吞吐量为193 MiB/s,写入吞吐量为168 MiB/s,这相当于分别为38.6微秒和43.3微秒的DPFS基准开销。
3.2 DPFS-NFS性能
在确定了虚拟化开销(通过峰值性能)之后,我们现在评估从主机到远程NFS服务器的完整I/O路径与从DPU(图1中的步骤1-6与A-D)的性能,当使用4 KiB块大小时(预热10秒,随后运行60秒)。我们选择4 KiB作为它是最常见的块大小之一,并且是与系统内存页的粒度相匹配的I/O请求大小。4 KiB I/O大小进一步强调了软件开销(内存分配、调度成本),因此突显出任何低效之处。
图2b显示了吞吐量(y轴,以MiB/s为单位)与I/O深度(x轴)的关系。主机NFS客户端(路径A-B)在I/O深度为3之前提供更好(11% – 21%)的读写吞吐量。然而,在I/O深度为4以上,DPFS从部分卸载的网络堆栈中获益,提供比主机NFS更好(12% – 32%)的吞吐量。然而,所有配置都不能在I/O深度为16以上进行扩展(请参见限制§3.5)。
我们在图2c中进一步分析了4 KiB I/O操作的延迟。如上所述,在I/O深度为1时,主机NFS比DPFS-NFS更快。对于DPFS-NFS,我们将开销分为两部分,即DPU引起的延迟(显示在底部的柱状图,38.6-43.3微秒)和软件延迟(上部,52.9-52.2微秒)。我们预计前一种延迟会随着新一代DPU的出现而改善。此外,我们使用带有Nvidia XLIO的libnfs来模拟套接字语义。我们预计,使用RDMA的本机libnfs实现也将能够降低用户空间NFS的开销。DPFS-NFS的用户空间NFS延迟(来自DPU的NFS的延迟,顶部部分)比主机NFS延迟低26.7% – 33%,这是由DPFS-NFS使用的硬件卸载网络堆栈导致的。
3.3 DPFS-KV性能
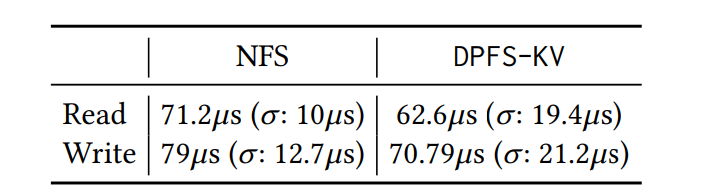
最后,我们证明通过将文件存储后端专门化为RAMCloud,DPFS可以为特定工作负载的部署提供性能优化。表3显示了我们访问完整的4 KiB文件的结果,这些文件存储在NFS和RAMCloud中(预热5秒,随后运行10秒)。这些文件被完整地访问(即单个I/O操作)。与主机NFS相比,DPFS-KV在读写操作上提供了7%-12%的延迟优势。
3.4 主机微架构分析
为了解释DPFS的效率提升,我们进行了低级微架构分析。我们测量了指令/操作(量化了I/O路径中的软件开销)、IPC(量化了代码路径效率)、分支预测失误率(量化了代码路径的可预测性)、L1 dCache失误率(量化了数据获取率)以及最后的dTLB失误率(量化了与内存管理相关的开销)。所有事件都是在主机CPU上使用带有–kernel-only标志的perf进行测量的,因此将主机NFS的内核内开销与DPFS-NFS进行了比较。
我们首先测量了一个空闲机器,持续了10分钟(5次运行,取平均值),然后使用128个I/O深度的随机4 KiB读/写(50%分布)持续了10分钟(5次运行,取平均值)。通过两者之差,我们量化了主机NFS和DPFS的主机文件系统客户端实现的成本(即virtio-fs、DPU上的DPFS-NFS)。
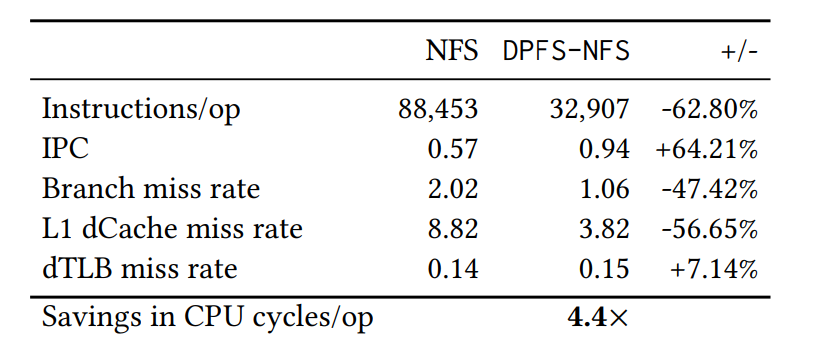
表4显示(1)与主机NFS相比,DPFS-NFS更轻量级,需要的指令数少62.80%,以完成随机4 KiB操作;(2)它具有更好的IPC,部分原因是较小的代码路径,但也是因为DPFS-NFS请求分发和处理的轮询性质;(3)DPFS-NFS具有较低的分支和L1 dCache失误率,说明了简化的执行轮廓。它的dTLB失误率略高,这归因于virtio-fs的页使用效率低(见§3.5)。总的来说,通过将每个I/O的指令和IPC结合起来,我们发现DPFS主机I/O路径(步骤1-6)比主机NFS(步骤A-D)更高效,提高了4.4倍。
3.5 局限性和未来展望
当前的工作受到一些限制,我们预计随着virtio-fs的使用变得普遍,这些限制将得到改善。首先,内核中当前的virtio-fs实现不支持多队列 [37],因此,DPFS目前只支持每个租户一个virtio队列。由于DPFS的实现限制,我们只能利用一个DPU线程来处理单个virtio队列,限制了图2a和图2b中实现的吞吐量。单个队列仅限制了每个租户的可用带宽,而不限制支持的租户数量。我们目前正在努力通过Nvidia BlueField-2上的SR-IOV [8] 添加对多租户的支持。
其次,FUSE报头使用过多的页(读I/O需要3个页,写I/O需要4个页)来存储它们的报头 [37]。由于Nvidia XLIO的内存瓶颈(与硬件紧密集成,大页,内存固定)在使用大量内存时,DPFS-NFS只能在DPU中配置最大64个页的virtio队列大小。在一个virtio-fs操作中至少有四个页的开销,因此DPFS-NFS只能限制在队列深度为16(64/4)。
第三,由于virtio-fs文件系统操作通过DPU的SoC复杂流动,Nvidia BlueField-2中较弱的硬件(ARM A72核心,单通道DDR3)[32]构成了一个显著的瓶颈。这个瓶颈可以从DPFS-null(图2a)和DPFS-NFS(图2b)的吞吐量差异中看出。由于TCP处理和产生的额外数据拷贝,DPFS-NFS仅能够达到DPFS-null的4 KiB吞吐量的约20%。
我们预计硬件/软件堆栈的下一次迭代将有助于减轻这些限制,并且通过紧密集成文件系统实现与硬件,以防止内存拷贝,将加速大块大小工作负载。
相关工作
所有云服务商都提供了面向大规模、多租户和高可用性的高性能、可扩展的文件系统服务。然而,如今,访问云文件系统服务的典型方式要么是通过NFS客户端(标准内核中的)[3, 12, 27],要么是在租户机器上运行云服务商的文件系统客户端代码[10, 11, 36]。这种方法在云租户和提供商之间提供了很差的隔离,并且消耗了大量的租户资源(CPU、RAM)。
随着DPU能力的提升[4, 5],在学术界和工业界中有许多项目探索了将它们用于虚拟化和加速各种云服务的可能性。例如,用于网络功能[9, 41, 42, 49],用于块存储[14, 15, 26, 28],用于键值和对象存储[23, 40, 45]。我们的工作沿着这个方向前进,专注于卸载和抽象文件系统服务,这是一个近期被忽视的领域。
与我们的论文最相关的工作有两个:(1)LineFS [16],它提供了一个利用DPU卸载耗费资源的后台任务的持久性内存分布式文件系统,以及(2)FISC [21],它是一个云原生文件系统,通过自定义的Virtio-Fisc设备接口,将整个文件系统卸载到基于FPGA的DPU和远程服务器。DPFS与这些工作在两个方面不同。首先,DPFS和FISC利用DPU卸载来进行虚拟化,通过将文件系统客户端与文件系统实现分离,减轻了主机CPU的负担,增加了云服务商对文件系统堆栈的控制。而LineFS则利用DPU卸载来提高性能。其次,DPFS与FISC的区别在于,它将文件系统实现卸载到现成的基于CPU的DPU上(例如Nvidia BlueField-2),并使用现有的virtio-fs主机软件堆栈,为实现不同的文件系统后端提供了一个开放的API。
结论
为了解决分布式文件系统提供轻量级客户端的挑战,我们提出使用DPU对文件系统API进行虚拟化和解耦。我们利用Linux virtio-fs软件堆栈将文件操作传递给DPU,云服务商可以在DPU上实现各种优化的网络/存储后端。在我们的评估中,我们证明了DPFS,我们的框架,轻量级(40微秒基本延迟,主机CPU开销降低了4.4倍),性能竞争力强,并且在主机上不需要任何配置或修改。